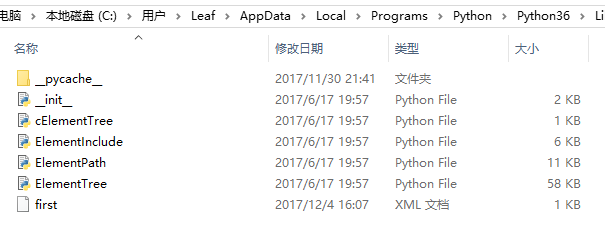
用的python3读取XML文件,一直报错是路径问题,而我的XML文件是和Python文件放在一块的,试了好多种方法始终解决不了这个问题,求助各位大神,我的问题具体出在哪里,该怎么修正,谢谢了!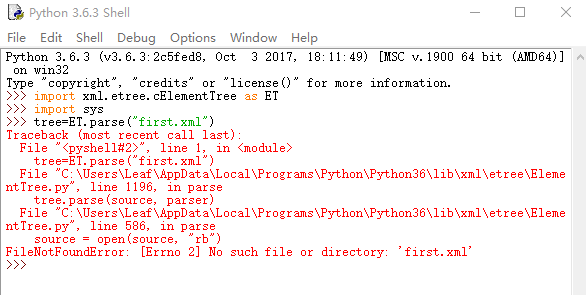

python3读取XML文件时一直是找不到文件

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

3条回答 默认 最新
 shonmark 2017-12-04 07:39关注
shonmark 2017-12-04 07:39关注你用的绝对路径吗?看看路径是\吗,都改成/试试还有这个文件是有扩展名的,要加.xml。
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2020-12-22 05:39Python是广泛用于处理XML数据的语言,它提供了xml.etree.ElementTree模块来解析、创建和修改XML文件。在SSD(Single Shot MultiBox Detector)训练数据中,VOC(PASCAL Visual Object Classes)格式的XML文件通常...
- 2021-01-21 15:29关于python读取xml文章很多,但大多文章都是贴一个xml文件,然后再贴个处理文件的代码。这样并不利于初学者的学习,希望这篇文章可以更通俗易懂的教如何使用python来读取xml文件。 什么是xml? xml即可扩展标记语言...
- 2020-12-10 01:08weixin_39904612的博客 /usr/bin/env python#coding=utf-8from xml.dom.minidom import parse, parseStringdef getText(nodelist):rc =''for node in nodelist:if node.nodeType == node.TEXT_NODE:rc = rc + node.datareturn rcdef ...
- 2024-09-24 14:53东眠的鱼的博客 关于python读取xml文章很多,但大多文章都是贴一个xml文件,然后再贴个处理文件的代码。这样并不利于初学者的学习,希望这篇文章可以更通俗易懂的教如何使用python 来读取xml 文件。什么是xml?xml即可扩展标记语言...
- 2025-11-15 16:54东眠的鱼的博客 关于python读取xml文章很多,但大多文章都是贴一个xml文件,然后再贴个处理文件的代码。这样并不利于初学者的学习,希望这篇文章可以更通俗易懂的教如何使用python来读取xml 文件。
- 2020-12-08 12:35weixin_39915815的博客 XML文件内容如下:10000iPhone9999920000特斯拉80000030000Mac Pro40000读取与搜索XML文件from xml.etree.ElementTree import parsedoc = parse('products.xml')# 通过XPath搜索子节点集合,然后对子节点集合进行遍历...
- 2020-09-17 14:26本文将详细讲解如何使用Python读取三种常见的配置文件格式:ini、yaml和xml。 **一、ini文件** ini文件是一种简单易读的文本格式,常用于存储应用程序的配置信息。其基本结构包括节(section)和键值对(key-value...
- 2020-06-12 16:56使用Python读取XML文件,并且如何读取数据集的内容,获得数据集的标签,将其运用到训练过程中,通过该文件学会如何读取XML文件的内容,最终实现自己的数据集读取
- 2023-03-17 09:00全能搬运大师的博客 xml解析常用两种方法:DOM和ElementTree
- 2022-11-27 20:04程序员老华的博客 关于python读取xml文章很多,但大多文章都是贴一个xml文件,然后再贴个处理文件的代码。这样并不利于初学者的学习,希望这篇文章可以更通俗易懂的教如何使用python来读取xml文件。
- 没有解决我的问题, 去提问

