图片说明](https://img-ask.csdn.net/upload/201803/02/1519966419_12980.png)

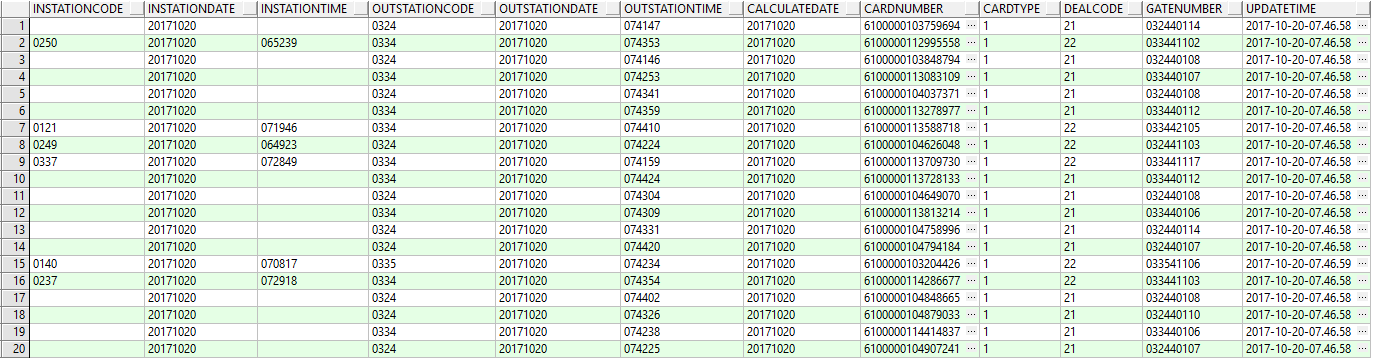
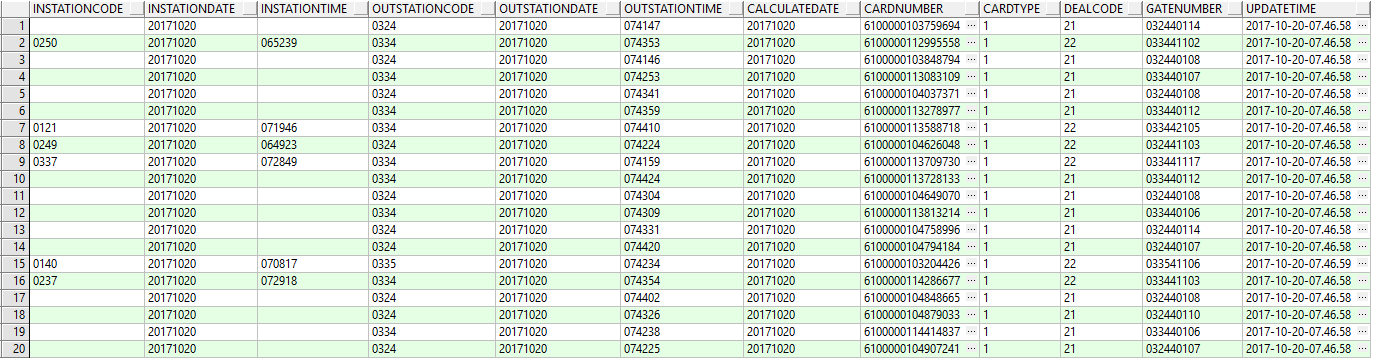
有一个表数据量每天存入数据3百万左右,现在千万级,要筛选表里一些数据,怎么查才能速度快一点

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


14条回答 默认 最新
 WalkingMonstrel 2018-03-02 06:54关注
WalkingMonstrel 2018-03-02 06:54关注这个问题够写一篇分析报告了。
1. 首先每天三百万数据,这张表再大,最后都会撑不住,横向分表是自然的事。估计最先想到的是按时间来分吧。
2. 查询速度的问题可使用的技术方案有很多,但先要做的是对业务查询的分析。找出瓶颈,才能有的放矢。试列举几种:
i 缓存,已查过的放内存,没查过的才查
ii 索引,合理利用索引,甚至构造自己的索引表
ii 并行,可以多线程/多进程甚至分布式
iV 分离读写,使用数据仓库,专门面对查询
V 预处理,我先查,等你来问的时候,我只是把结果告诉你,能不快么?最后一个方针:与其榨出每条查询语句的效率,不如从架构上总体设计,这才是正确的展开方式。本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2018-03-02 04:54回答 14 已采纳 这个问题够写一篇分析报告了。 1. 首先每天三百万数据,这张表再大,最后都会撑不住,横向分表是自然的事。估计最先想到的是按时间来分吧。 2. 查询速度的问题可使用的技术方案有很多,但先要做的是对业
- 2022-11-04 13:41回答 4 已采纳 这个简单,代码如下,有帮助的话采纳一下哦! import glob import psycopg2 as psy import os filepattern = r'E:\study\Python\
- 2017-11-28 02:24回答 3 已采纳 如果你想自己实现,使用本身自带的定位API,百度都是的,或者使用百度地图定位,这种更加简单,至于存入数据库,可以用一个字段来保存精度以及纬度,格式 可以是这样 : latitude,laln
- 2019-09-16 11:07代码学习的博客 这个问题够写一篇分析报告了。 首先每天三百万数据,这张表再大,最后都会撑不住,横向分表是自然的事。估计最先想到的是按时间来分吧。 查询速度的问题可使用的技术方案有很多,但先要做的是对业务查询的分析。找...
- 2022-03-28 12:28回答 1 已采纳 按这个需求, 看实际跑的脚本, 可能合适的数据较少修改随机值范围小一些,相等机会大一些 from threading import Thread from time import sleep from
- 2022-01-24 01:28回答 8 已采纳 import pandas as pd import glob import os # 获取当前路径 cwd = os.getcwd() # 要拼接的文件夹及其完整路径,注不要包含中文 ## 待读
- 2018-06-26 21:20回答 3 已采纳 问题一:阁下的想法和初始想法不符合啊 for(i=0;i<s1;i++) { //判断原数组中是否含有相同元素 //含有则退出
- 2018-12-02 00:37lbxxzt的博客 1、索引,建立索引是数据库优化各种方案之中成本最低,见效最快的解决方案,一般来讲,数据库规模在几十万和几百万级别的时候见效最快,即便是有不太复杂的表关联,也能大幅度提高sql的运行效率,这个在我们以前的...
- 2021-12-25 23:58回答 1 已采纳 fseek的是文件结尾,不是最后一个结构体首地址
- 2017-11-05 03:44回答 1 已采纳 能弹出数据是什么意思?既然弹出的有数据,怎么会没有值呢?
- 2021-07-29 12:01回答 1 已采纳 使用触发器 CREATE TRIGGER '触发器名称' BEFORE DELETE ON '删除的主表名称' FOR EACH ROW BEGIN INSERT INTO '备份表名称' SELEC
- 2022-07-31 16:37Ray_Shawn的博客 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理各大网站或者App中用户的动作流数据。用户行为数据是后续进行业务分析和优化的重要数据资产,这些数据通常以处理日志和日志聚合的方式解决。是基于Lucene...
- 2023-03-13 11:21回答 2 已采纳 这是一个json结构的字符串,"a":"b", 可以建一个实体类,左边a是字段名称,把你需要的数据的左边作为你字段的名称,然后用JSONObject.parseObject方法来解析成对象例,实体类:
- 2022-07-26 19:18Andy_shenzl的博客 有人可能会问了我的数据就存放在自己电脑的excel表里或者其他的本地文件就可以了,为什么还要搞个数据库呢?这是因为数据库比excel有更多的优势。数据库可以存放大量的数据,允许很多人同时使用里面的数据。前面讲的...
- 2021-11-05 17:12wzy0623的博客 对于每一种技术,先要理解相关的概念和它之所以出现的原因,这对于我们继续深入学习其技术细节大有裨益。实时数据仓库首先是个数据仓库,只是它优先考虑数据的时效性问题。因此本篇开头将介绍业界公认的数据仓库定义...
- 2023-10-25 19:09嗎嗎的博客 大数据面试基础知识囊括hadoop、spark、hive、kafka等
- 2021-02-12 13:52半张老头的博客 1. 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?方案1:可以估计每个文件安的大小为50G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 执行 virtuoso 命令后,界面没有,cadence 启动不起来
- ¥50 comfyui下连接animatediff节点生成视频质量非常差的原因
- ¥20 有关区间dp的问题求解
- ¥15 多电路系统共用电源的串扰问题
- ¥15 slam rangenet++配置
- ¥15 有没有研究水声通信方面的帮我改俩matlab代码
- ¥15 ubuntu子系统密码忘记
- ¥15 信号傅里叶变换在matlab上遇到的小问题请求帮助
- ¥15 保护模式-系统加载-段寄存器
- ¥15 电脑桌面设定一个区域禁止鼠标操作