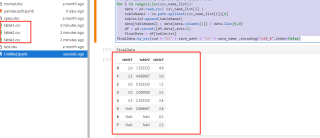
我想用python 合并一组表格,麻烦给写可直接用的代码
目录D:/001 文件下有多个cvs表(表1到表?),
把第二列(B2到B?,数量不固定)除以固定值A2,
得到新的列合并输出在all.csv中,放同目录下
第一行输出表格文件名,原表第一行数据不需要,
如图分表第3列是需要的生成的数据合并到总表
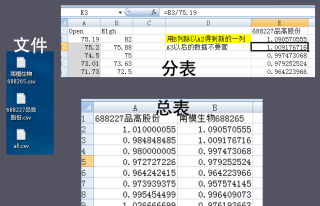
下面是一组参考代码,用来改改可能快一点
import pandas as pd
import os
# 获取当前路径
cwd = os.getcwd()
# 要拼接的文件夹及其完整路径,注不要包含中文
# 待读取批量csv的文件夹
read_path = 'data_Q1_2018'
# 待保存的合并后的csv的文件夹
save_path = 'data_Q1_2018_merge'
# 待保存的合并后的csv
save_name = 'Modified.csv'
# 修改当前工作目录
os.chdir(read_path)
# 将该文件夹下的所有文件名存入列表
csv_name_list = os.listdir()
# 读取第一个CSV文件并包含表头,用于后续的csv文件拼接
df = pd.read_csv( csv_name_list[0])
# 读取第一个CSV文件并保存
df.to_csv( cwd + '\\' + save_path + '\\' + save_name , encoding="utf_8",index=False)
# 循环遍历列表中各个CSV文件名,并完成文件拼接
for i in range(1,18):
df = pd.read_csv( csv_name_list[i] )
df.to_csv(cwd + '\\' + save_path + '\\' + save_name ,encoding="utf_8",index=False, header=False, mode='a+')