如图所示的网页HTML标签,现想用正则表达式将div class='dg000'或者div class='dgfff'的标签提取出来,而不包括class='dgfff banner-box'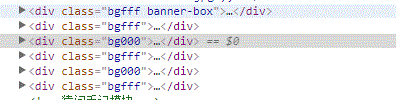
用如下语句提取实现不了,原因是什么呢?
datas=soup.find_all('div',{'class':'re.compile(''bg[f,0]{3}$)})

如图所示的网页HTML标签,现想用正则表达式将div class='dg000'或者div class='dgfff'的标签提取出来,而不包括class='dgfff banner-box'
用如下语句提取实现不了,原因是什么呢?
datas=soup.find_all('div',{'class':'re.compile(''bg[f,0]{3}$)})
 分享
分享
soup.findAll("div", attrs={"class":re.compile(r'bg[f0]{3}$')})试试
分享


