
本人使用flume1.60版本和kafka0.8.2.2版本进行连接,配置如下:
a0.sources.r1.type = xiaomu.flume.source.TailFileSource
a0.sources.r1.filePath = /root/access2.txt
a0.sources.r1.posiFile = /root/posi2.txt
a0.sources.r1.interval = 2000
a0.sources.r1.charset = UTF-8
a0.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a0.channels.c1.capacity = 1000
a0.channels.c1.transactionCapacity = 1000
a0.channels.c1.brokerList=slave1:9092,slave4:9092,slave3:9092
a0.channels.c1.topic=usertest3
a0.channels.c1.zookeeperConnect=slave2:2181,slave5:2181,slave6:2181
a0.channels.c1.parseAsFlumeEvent = false
但是我echo "xxx" >> access2.txt之后,在kafka那边就不一样了,比如我打xiaomu,就会出来两行,一行是xiaomum,第二行是空白,还有时候是一行但是开头有一个方框,如图所示: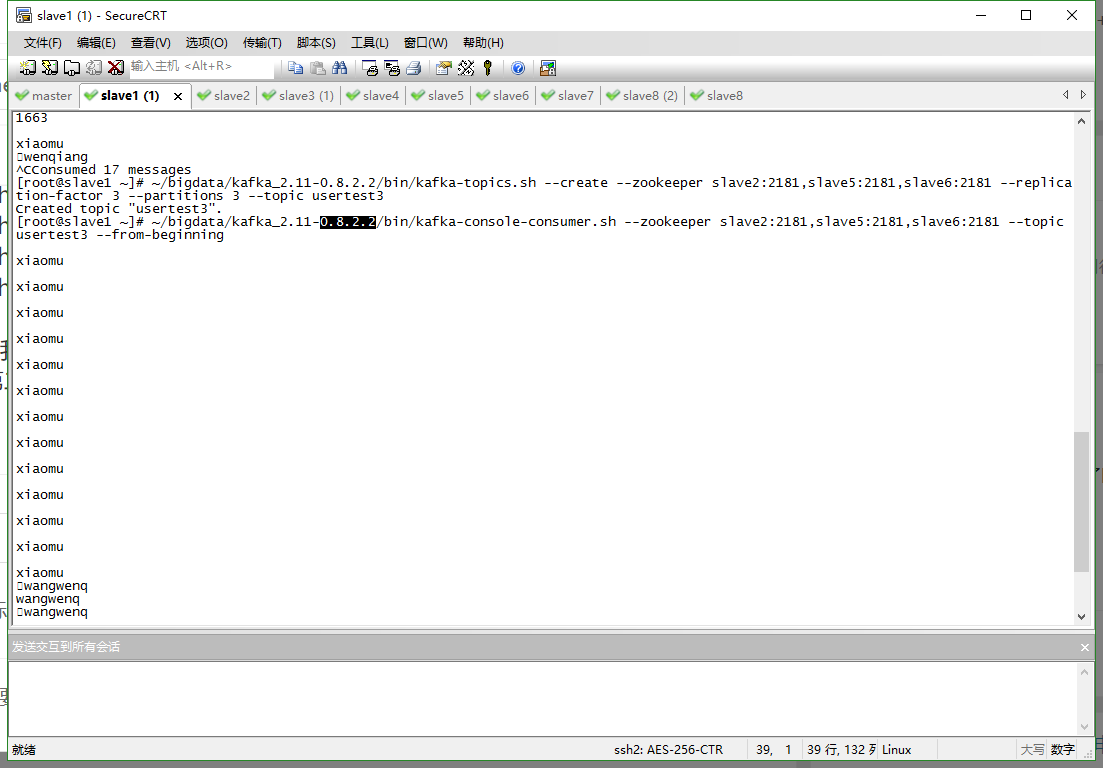
这个怎么解决呀?求助各位大神了!




