
在学习《python数据分析基础》2.6节:读取多个CSV文件时发现一个问题,这一节给了一个
脚本用于计算某路径下所有csv文件的行,列数.
import csv
import sys
import os
import glob
input_path=sys.argv[1]
file_counter=0
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
row_counter = 1
with open(input_file,'r',newline='') as csv_in_file:
filereader = csv.reader(csv_in_file)
header=next(filereader,None)
for row in filereader:
row_counter+=1
print('{0!s}:\t{1:d} rows \t{2:d} columns'.format(\
os.path.basename(input_file),row_counter,len(header)))
file_counter+=1
print('Number of files:{0:d}'.format(file_counter))
原本书中给的数据文件是这样的: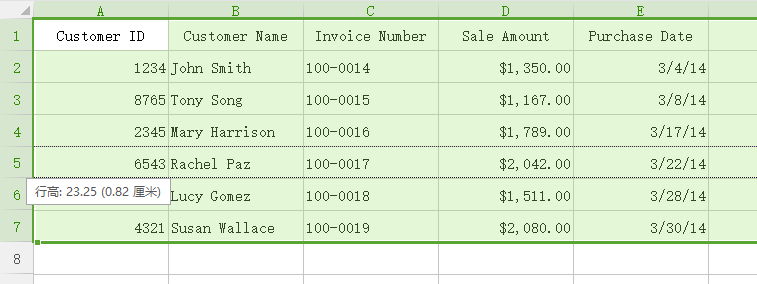
数据是书上给的,7行5列的数据,csv文件是我自己手动录入的.
由于WPS表格单元格过小,在录入数据后拉伸各行列宽,高: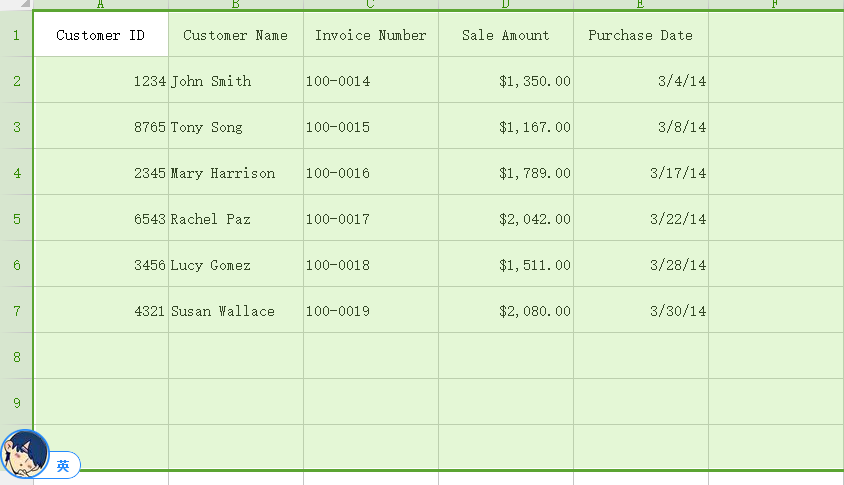
有部分空白行被我批量拉伸宽高时选中
然后执行脚本,发现被批量拉伸宽高时选中的空白行也被计算入文件的行数:
将这些被拉伸宽高的空白行删去后再次执行脚本,结果正常:
综上,发现在WPS里打开CSV文件后如果在拉伸各行列的高宽时,选中了没有内容的空白行,
这些空白行会在文件读取对象中被迭代,导致空白行被计算,请问这是为什么?





