
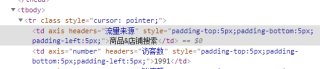

如上图,请教大佬如何提取出访客数1991的数据?我的想法是类似pandas中筛选表格的条件,假设这个表格为df
df[df['流量来源']=='商品&店铺搜索']['访客数']
流量来源的商品店铺搜索我用的是下面代码获取的
sources = soup.find_all('td',{'headers':'流量来源'})
for source in sources:
s = source.get_text()
请教大佬如何用python实现这种同级的信息提取?因为商品&店铺搜索没有在访客数的属性里,不知道应该如何操作






