环境是python3.6,django是最新的版本。
问题:仅仅是创建一个django项目,然后运行。
就会提示这个编码格式的错误。
找了很久,也没在网上找到解决方法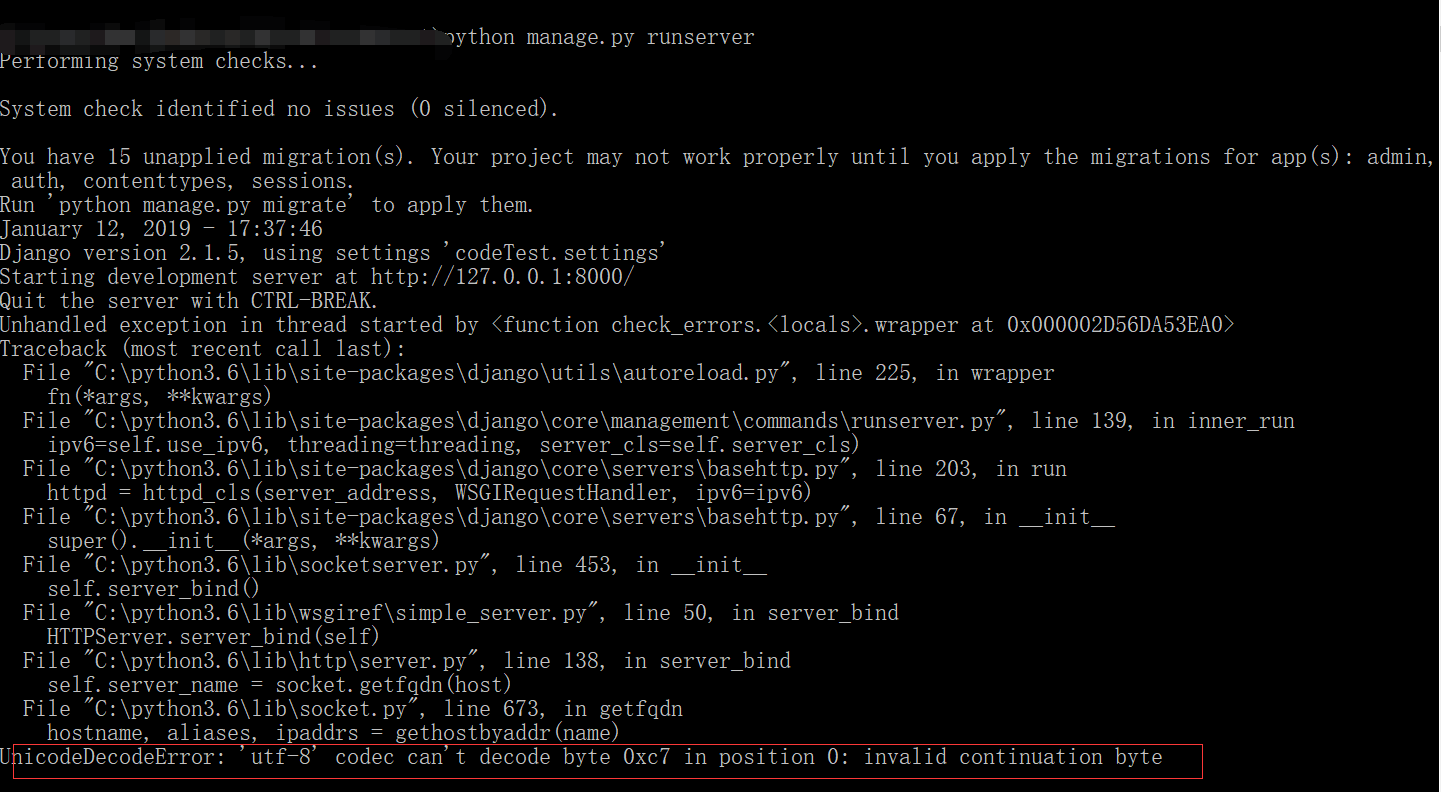
还望有人能帮我解决这个问题,不然工作没法在自己本上允许了,很难受。谢谢大家了。
还有,我如果启动时候换个地址和端口启动,程序就可以正常跑起来。
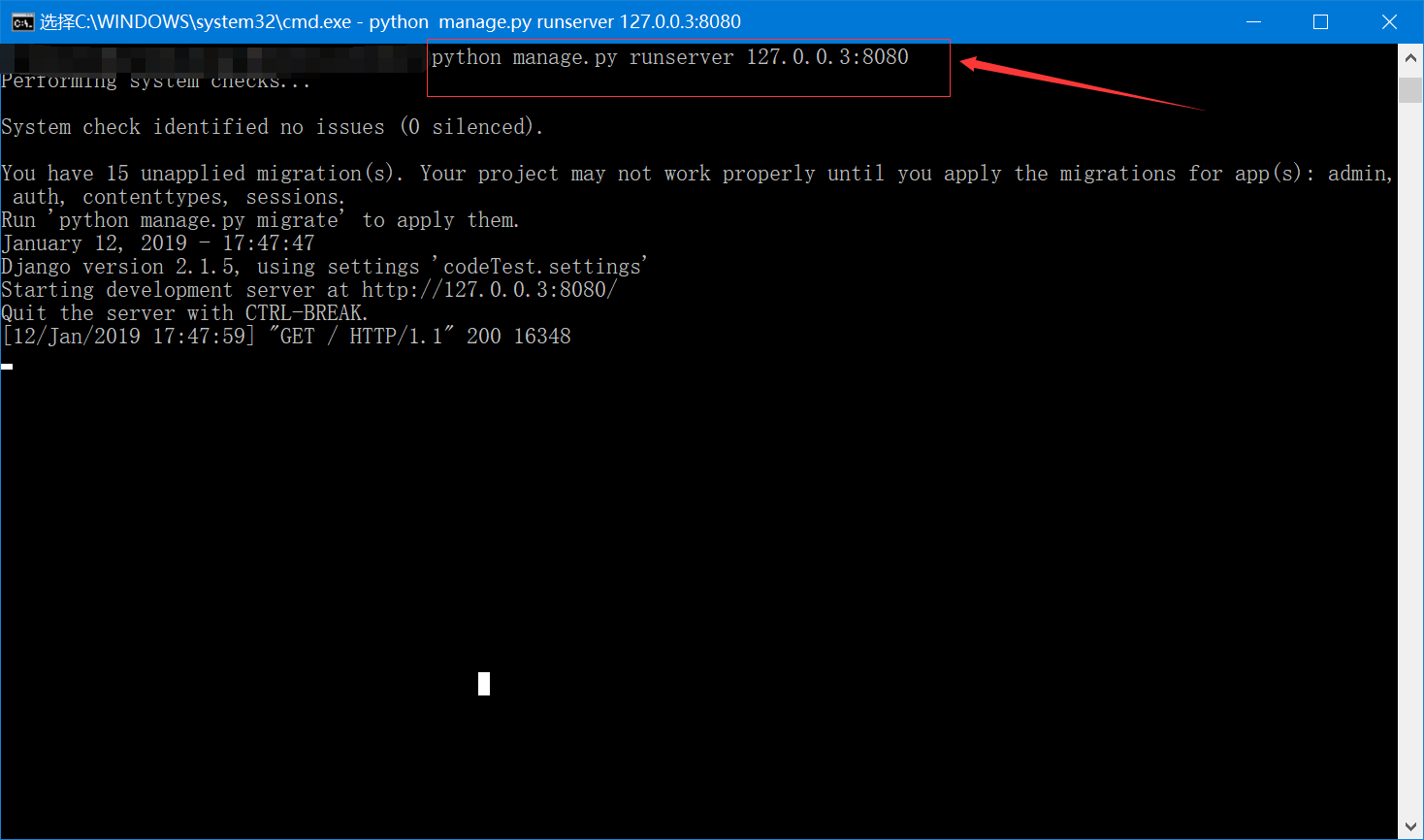
请大家能告诉我为什么。再次谢谢大家了。

环境是python3.6,django是最新的版本。
问题:仅仅是创建一个django项目,然后运行。
就会提示这个编码格式的错误。
找了很久,也没在网上找到解决方法
还望有人能帮我解决这个问题,不然工作没法在自己本上允许了,很难受。谢谢大家了。
还有,我如果启动时候换个地址和端口启动,程序就可以正常跑起来。
请大家能告诉我为什么。再次谢谢大家了。
 分享
分享 老子找到问题根源了,真是个大坑。出现这个问题的根本原因是本机器的字符编码有问题。具体改正的方法是:
在小娜里面搜索地区。然后更改国家或地区---管理语言设置---在弹出的地域里面点击‘更改系统区域设置’---把‘BETA版:使用utf-8’那个选上,重启。
OK了。真是个坑人的地方。
分享 UnicodeDecodeError: 'ascii' codec can't decode byte 0xe9 in position 0: ordinal not in range(128) 解决
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe9 in position 0: ordinal not in range(128) 解决
