

#需求:获取三国演义小说所有的章节标题和章节内容
#地址:https://www.shicimingju.com/book/sanguoyanyi.html
import lxml
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
headers = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 88.0.4324.182 Safari / 537.36 Edg /88.0.705.81'
}
page_text = requests.get(url,headers=headers).text
print(page_text)
到这里爬取到的网页中文显示是乱码
原网页编码显示为‘UTF-8’,
尝试用page_text.encoding = "utf-8",但是就直接报错
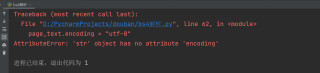
用 print(type(page_text)),查看显示数据类型为str 。










