使用CrawlSpider建立rules规则之后,比如该规则是下一页的url,然后添加callback指定解析函数,然后我发现,CrawlSpider直接就从下一页开始发出的请求,根本就没有从前面定义的start_ursl开始请求,导致获取到的数据是从网站第二页开始获取的,这肯定不是我想要的结果,这个问题如何破解???
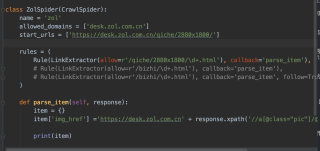

使用CrawlSpider建立rules规则之后,比如该规则是下一页的url,然后添加callback指定解析函数,然后我发现,CrawlSpider直接就从下一页开始发出的请求,根本就没有从前面定义的start_ursl开始请求,导致获取到的数据是从网站第二页开始获取的,这肯定不是我想要的结果,这个问题如何破解???
 分享
分享




