

我在用Python处理气象数据时出现的问题。按照工作需要,我在对ERA5(下载链接:链接:https://pan.baidu.com/s/1alH1cLXOAGYMz67dPdoZ2w 提取码:c4b2 )和CRU_TS v4.04(下载链接:链接:https://pan.baidu.com/s/1c4IVFI-jetxuEThaCqml1g 提取码:w5r0 )的气温数据进行分析,计算相关系数(CC),后面计算的代码来源于网络,前面的代码作用的统一经纬度分辨率(把ERA5经纬度统一成与CRU_TS v4.04一样的0.5度乘0.5度),现在确认在统一经纬度分辨率没有问题。CRU_TS v4.04没有海洋和南极地区的数据,所以存在NaN空值,在如下的代码运算之后,
import pandas as pd
import pylab as plt
from netCDF4 import Dataset
import numpy as np
file_0 = 'G:\\Data\\TP_and_2mT_1950-1978_Monthly.nc'
file_A = 'G:\\Data\\cru_ts4.04.1901.2019.tmp.dat.nc'
a = Dataset(file_0)
b = Dataset(file_A)
t2m = a.variables["t2m"][:]
tmp = b.variables["tmp"][:]
t2m = t2m[-1]
num = 1
num0 = 1
for i in range(720):
t2m = np.delete(t2m, num, axis=1)
num = num + 1
for i in range(360):
t2m = np.delete(t2m, num0, axis=0)
num0 = num0 + 1
t2m = np.delete(t2m, -1, axis=0)
t2m = t2m - 273.15
t2m_xin = []
for i in range(0, len(t2m)):
for j in t2m[i]:
t2m_xin.append(j)
tmp = tmp[935]
tmp_new = []
for i in range(0, len(tmp)):
for j in tmp[i]:
tmp_new.append(j)
era5_list = t2m_xin
cru_ts_list = tmp_new
g_s_m = pd.Series(era5_list) # 利用Series将列表转换成新的、pandas可处理的数据
g_a_d = pd.Series(cru_ts_list)
corr_gust = round(g_s_m.corr(g_a_d), 4) # 计算标准差,round(a, 4)是保留a的前四位小数
print('corr_gust :', corr_gust)
# 最后画一下两列表散点图,直观感受下,结合相关系数揣摩揣摩
plt.scatter(era5_list, cru_ts_list)
plt.title('corr_gust :' + str(corr_gust), fontproperties='SimHei') # 给图写上title
plt.show()
报错:
Traceback (most recent call last):
File "G:\Data_dispose\CC.py", line 37, in <module>
corr_gust = round(g_s_m.corr(g_a_d), 4) # 计算标准差,round(a, 4)是保留a的前四位小数
File "C:\Users\Liu Huageng\AppData\Roaming\Python\Python39\site-packages\pandas\core\series.py", line 2327, in corr
return nanops.nancorr(
File "C:\Users\Liu Huageng\AppData\Roaming\Python\Python39\site-packages\pandas\core\nanops.py", line 71, in _f
return f(*args, **kwargs)
File "C:\Users\Liu Huageng\AppData\Roaming\Python\Python39\site-packages\pandas\core\nanops.py", line 1459, in nancorr
return f(a, b)
File "C:\Users\Liu Huageng\AppData\Roaming\Python\Python39\site-packages\pandas\core\nanops.py", line 1480, in func
return np.corrcoef(a, b)[0, 1]
File "<__array_function__ internals>", line 5, in corrcoef
File "C:\Users\Liu Huageng\AppData\Local\Programs\Python\Python39\lib\site-packages\numpy\lib\function_base.py", line 2551, in corrcoef
c = cov(x, y, rowvar)
File "<__array_function__ internals>", line 5, in cov
File "C:\Users\Liu Huageng\AppData\Local\Programs\Python\Python39\lib\site-packages\numpy\lib\function_base.py", line 2456, in cov
avg, w_sum = average(X, axis=1, weights=w, returned=True)
File "<__array_function__ internals>", line 5, in average
File "C:\Users\Liu Huageng\AppData\Local\Programs\Python\Python39\lib\site-packages\numpy\lib\function_base.py", line 415, in average
if scl.shape != avg.shape:
AttributeError: 'float' object has no attribute 'shape'
随后,我用简单的数据类型转换,通过遍历列表里的数据,变成float类型数据,代码如下(第31-34行改动),
import pandas as pd
import pylab as plt
from netCDF4 import Dataset
import numpy as np
file_0 = 'G:\\Data\\TP_and_2mT_1950-1978_Monthly.nc'
file_A = 'G:\\Data\\cru_ts4.04.1901.2019.tmp.dat.nc'
a = Dataset(file_0)
b = Dataset(file_A)
t2m = a.variables["t2m"][:]
tmp = b.variables["tmp"][:]
t2m = t2m[-1]
num = 1
num0 = 1
for i in range(720):
t2m = np.delete(t2m, num, axis=1)
num = num + 1
for i in range(360):
t2m = np.delete(t2m, num0, axis=0)
num0 = num0 + 1
t2m = np.delete(t2m, -1, axis=0)
t2m = t2m - 273.15
t2m_xin = []
for i in range(0, len(t2m)):
for j in t2m[i]:
t2m_xin.append(j)
tmp = tmp[935]
tmp_new = []
for i in range(0, len(tmp)):
for j in tmp[i]:
tmp_new.append(j)
tmp_new_0 = []
for k in range(len(tmp_new)):
k = float(k)
tmp_new_0.append(k)
era5_list = t2m_xin
cru_ts_list = tmp_new_0
g_s_m = pd.Series(era5_list) # 利用Series将列表转换成新的、pandas可处理的数据
g_a_d = pd.Series(cru_ts_list)
corr_gust = round(g_s_m.corr(g_a_d), 4) # 计算标准差,round(a, 4)是保留a的前四位小数
print('corr_gust :', corr_gust)
# 最后画一下两列表散点图,直观感受下,结合相关系数揣摩揣摩
plt.scatter(era5_list, cru_ts_list)
plt.title('corr_gust :' + str(corr_gust), fontproperties='SimHei') # 给图写上title
plt.show()
确实没有报错,但是CRU_TS v4.04的数据已经发生改变,结果完全不符合实际情况,如图:
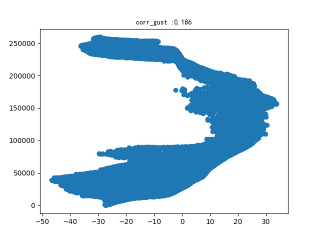
可以看出横坐标为ERA5的气温数据正常,纵坐标数据已经“废了”,为什么会这样?这么解决?刚入门编程不到半年的小白向大佬们请教。





