我的数据集一共有47447张图片,用40000张来做训练集,剩下的用做测试集,batch=32,epoch=100,训练的过程中随手记录了训练到目前的准确率数值啥的,目前进行了20多个epoch,数据都转化为float了,大小也都一样,这属不属于过拟合?如果是的话我还需要继续训练么?我增大batch数量会不会好一点?
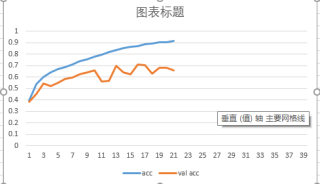

我的数据集一共有47447张图片,用40000张来做训练集,剩下的用做测试集,batch=32,epoch=100,训练的过程中随手记录了训练到目前的准确率数值啥的,目前进行了20多个epoch,数据都转化为float了,大小也都一样,这属不属于过拟合?如果是的话我还需要继续训练么?我增大batch数量会不会好一点?
 分享
分享
 关注
关注
问题分析:
很有可能是过拟合了!
解决方案:
(1)增加Dropout,随机断开神经网络之间的连接,减少每次训练时实际参与计算的模型的参数量,从而减少了模型的实际容量,来防止过拟合。
(2)增加正则化,这是通过在损失函数上添加额外的参数稀疏性惩罚项(正则项),来限制网络的稀疏性,以此约束网络的实际容量,从而防止模型出现过拟合。
(3)数据增强,即增加训练样本,这也是解决过拟合最直接的一种方式。
(4)调整网路,选用更轻便的网络架构,或者去掉原来网络中的某些卷积层,防止过度拟合。
以上的解决方案,可以具体参考我之前的博客专栏:https://blog.csdn.net/wjinjie/category_9766908.html
最后,答题不易,如果觉得我的回答对你有帮助,那就请给个采纳吧~
分享


