hotel <- read.csv("D:/Download/评论.txt")
segmentCN (hotel)
edit(hotel)
segmentCN("D:/Download/评论.txt")
前两行代码报错:Error in segmentCN(hotel) : Please input character!
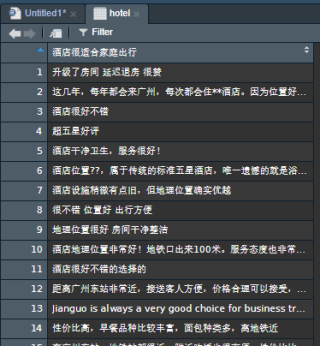
第三行代码数据表
第四行代码结果:[1] "D" "Download" "评论" "txt"
问:为什么不能直接读取文件来分词?

hotel <- read.csv("D:/Download/评论.txt")
segmentCN (hotel)
edit(hotel)
segmentCN("D:/Download/评论.txt")
前两行代码报错:Error in segmentCN(hotel) : Please input character!
第三行代码数据表
第四行代码结果:[1] "D" "Download" "评论" "txt"
问:为什么不能直接读取文件来分词?
 分享
分享
segmentCN的用法是:segmentCN(strwords, analyzer = c("default", "hmm", "jiebaR", "fmm", "coreNLP"), nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), ...) ,第一个参数是中文字符串向量,你直接用数据框传入当然会报错。你在读取数据后,将数据转换成一个字符串向量即可。示例:
library(Rwordseg)
hotel <- read.csv("F:\\2021\\rtest\\meidi_jd.txt")
for (h in hotel){
ht=paste(h)
}
edit(hotel)
edit(ht)
segmentCN(ht) 分享



