就比如说这样的数据集做预测,Category那一列怎么处理比较合适?还有Category和Genres两列比较相似,如何处理比较妥当?(整个数据集共一万多条)
还有Content Rating那一列,其中大部分都是everyone,但是也有一些别的像少数民族那样出现,那么对于这样特征的数据怎么处理比较合适呢?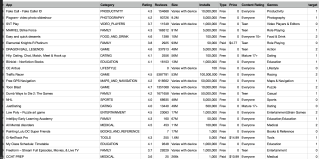

就比如说这样的数据集做预测,Category那一列怎么处理比较合适?还有Category和Genres两列比较相似,如何处理比较妥当?(整个数据集共一万多条)
还有Content Rating那一列,其中大部分都是everyone,但是也有一些别的像少数民族那样出现,那么对于这样特征的数据怎么处理比较合适呢?
 分享
分享
这种直接使用类别的index编码,在分类的时候直接转换成one hot后经过交叉熵计算loss反向传播就行了。如有帮助请采纳
分享



