网站为中国证券网 “http://www.cnstock.com/”
使用jsonp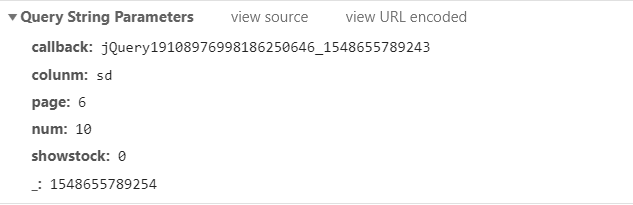

访问这个传递json数据的Request URL时,出现了404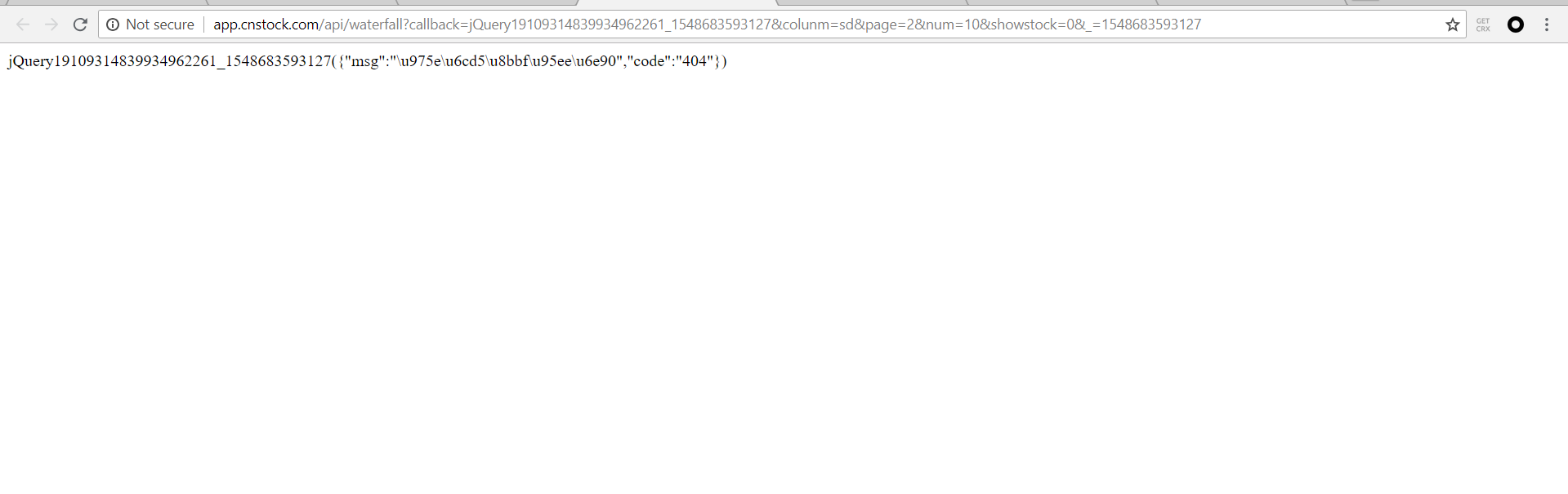
想请教一下如何解决

网站为中国证券网 “http://www.cnstock.com/”
使用jsonp
访问这个传递json数据的Request URL时,出现了404
想请教一下如何解决
 分享
分享
用抓包工具对照下,你这个返回了404是返回的json里的数据里面有一个404,而不是http返回了404的状态,可能是服务器判定你的请求不合法,丢失参数等,所以返回了一个错误信息。
可能的原因除了参数不合法,对照抓包数据检查
(1)referer字段
(2)cookie
(3)是否不允许get,需要post
(4)是否频繁访问,导致服务器有反爬虫的限制,换ip再试
分享



