
我现在有一个dataframe 通过cunt 列汇总得到一个新列(最后一列) 但是汇总数33每行都有,怎样只保留一行有数字,用过duplicates 方法 结果只能保留一行。我想保留前面所有行正常数据,只最后一列显示汇总数字即可。


我现在有一个dataframe 通过cunt 列汇总得到一个新列(最后一列) 但是汇总数33每行都有,怎样只保留一行有数字,用过duplicates 方法 结果只能保留一行。我想保留前面所有行正常数据,只最后一列显示汇总数字即可。
 分享
分享
没太看懂,你是想要这种效果么?
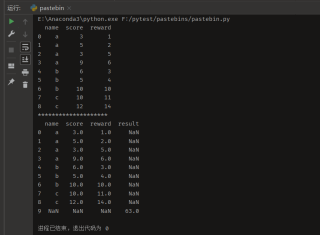
import pandas as pd
# a = pd.read_excel('123.xlsx')
list1 = [['a', 3, 1], ['a', 5, 2], ['a', 3, 5], ['a', 9, 6], ['b', 6, 3], ['b', 5, 4], ['b', 10, 10], ['c', 10, 11],
['c', 12, 14]]
b = pd.DataFrame(list1, columns=['name', 'score', 'reward'])
# b.loc[0, 'result'] = 3
print(b)
b.loc[9, 'result'] = b['score'].sum()
print('*' * 20)
print(b)
 系统已结题
9月18日
系统已结题
9月18日 已采纳回答
9月10日
创建了问题
9月9日
已采纳回答
9月10日
创建了问题
9月9日


