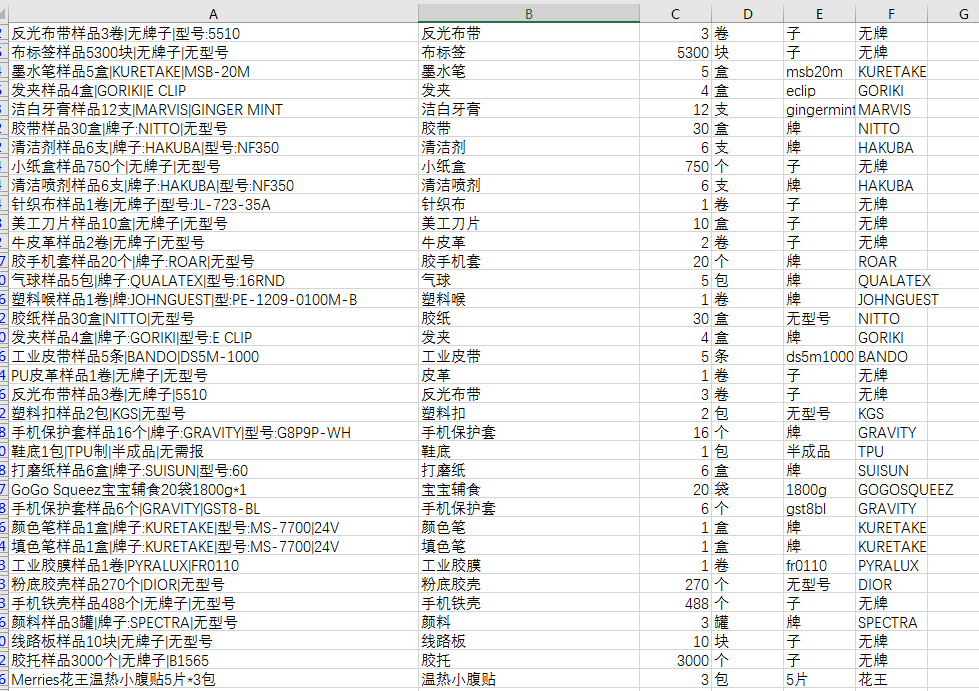
如图所示,第一列是商品信息,从里面提取出五维信息:品名,数量,单位,规格,品牌。图里面的结果是利用正则化的想法去做的。
现在先用NLP的一些方法做,没有接触过NLP,跪求各位大佬给个思路。
收起
现在先用NLP的一些方法做,没有接触过NLP,跪求各位大佬给个思路
报告相同问题?

 分享
分享


