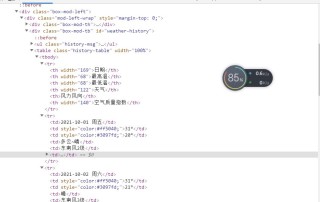
网页源代码,想要爬取历史天气
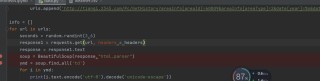
爬取代码如图↑
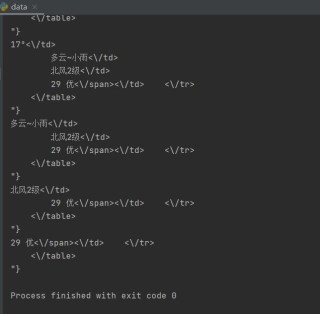
运行结果如图↑
为什么会带上这个结束标签呢?用了find()函数居然得到了一样的结果,而且find函数搭配string显示None,说明这个标签里嵌了不止一个子标签?怎么去掉标签!!求问

爬取代码如图↑
 分享
分享
请求返回的就是一个带td等标签(表格格式数据)的json数据,可用字符串方法进行处理,推荐使用pandas的read_html去读取表格更为简便,用如下方式解决:
for url in urls:
seconds=random.randint(1,5)
res=requests.get(url,headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.38'})
res.encoding=res.apparent_encoding
time.sleep(seconds)
js=res.json()
df=pd.read_html(js['data'])[0]
print(df)
运行结果:
日期 ... 空气质量指
数
0 2021-05-01 周六 ... 52 良
1 2021-05-02 周日 ... 38 优
2 2021-05-03 周一 ... 45 优
。。。
如对你有帮助,请点击我回答右上角【采纳】按钮采纳支持一下。
分享 系统已结题
10月25日
系统已结题
10月25日 已采纳回答
10月17日
创建了问题
10月16日
已采纳回答
10月17日
创建了问题
10月16日




