大家好:
在网上看到了一段关于使用python爬虫爬取小猪短租上房源信息的代码(请见出处: https://www.cnblogs.com/november1943/p/5230924.html )
根据这个代码想要做一些拓展:额外爬取:房屋面积 (如图所示)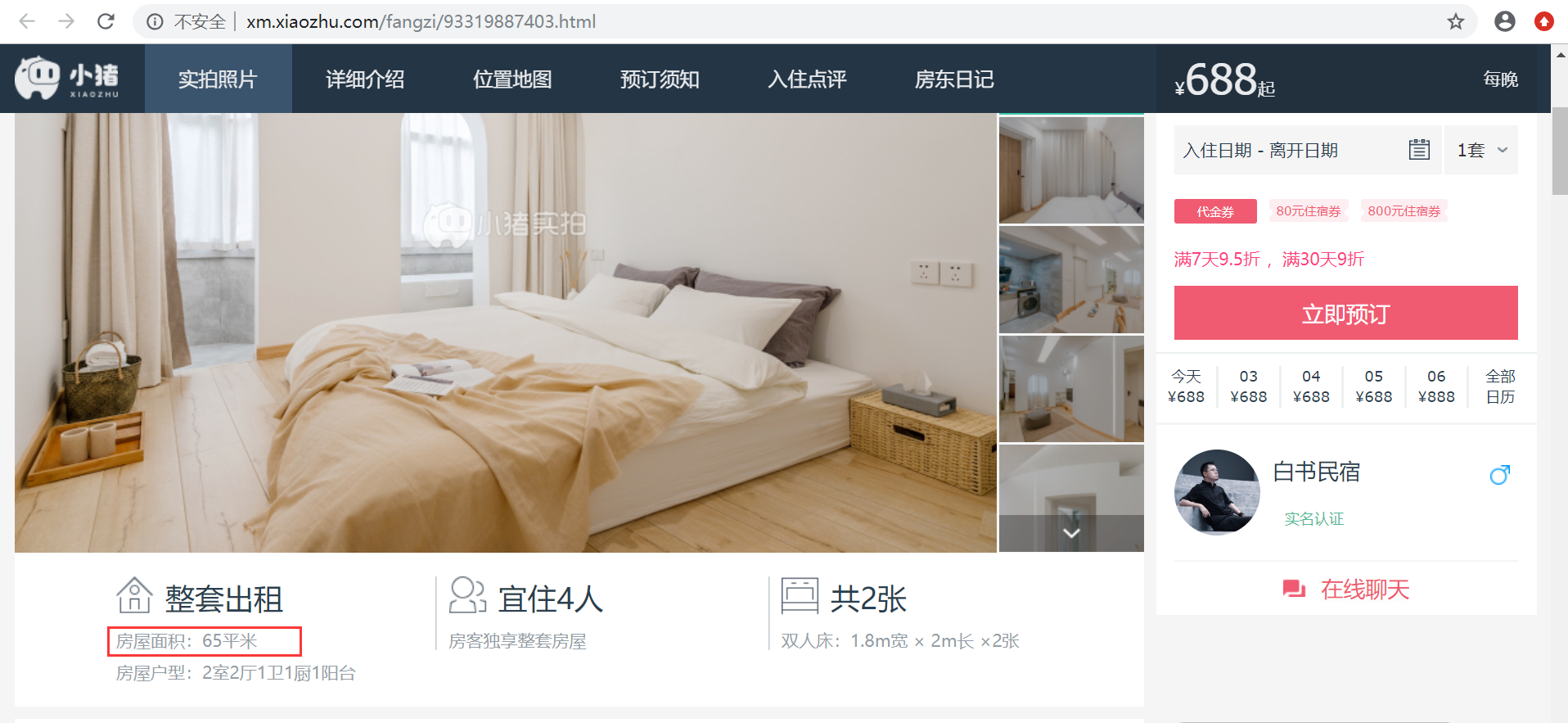
从后台来看相关的面积信息位置如下
打算使用b4库的 soup.select()功能抓取信息,但是不知道该如何告诉python 这条信息的路径...
请问大家这个信息的路径应该如何表达?
求点播 感谢大家

大家好:
在网上看到了一段关于使用python爬虫爬取小猪短租上房源信息的代码(请见出处: https://www.cnblogs.com/november1943/p/5230924.html )
根据这个代码想要做一些拓展:额外爬取:房屋面积 (如图所示)
从后台来看相关的面积信息位置如下
打算使用b4库的 soup.select()功能抓取信息,但是不知道该如何告诉python 这条信息的路径...
请问大家这个信息的路径应该如何表达?
求点播 感谢大家
 分享
分享
没用过select,但看样子是这样用的
from bs4 import BeautifulSoup
import requests
url = 'http://bj.xiaozhu.com/fangzi/1508951935.html'
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text, 'lxml')
title = soup.select('div.pho_info > h4 ')[0].text
address = soup.select('div.pho_info > p ')[0].get('title')
price = soup.select('div.day_l > span')[0].text
area = soup.select('li.border_none >p ')[0].next
first_pic = soup.select('#curBigImage')[0].get('src')
landlord_pic = soup.select('div.member_pic > a > img')[0].get('src')
landlord_name = soup.select('div.w_240 > h6 > a')[0].text
if soup.select('span[class="member_girl_ico"]'):
landlord_gender = 'female'
else:
landlord_gender = 'male'
data = {
'title': title,
'address': address,
'price': price,
'area':area,
'first_pic': first_pic,
'landlord_pic': landlord_pic,
'landlord_name': landlord_name,
'landlord_gender': landlord_gender
}
print(data)
 已采纳回答
9月14日
已采纳回答
9月14日


