

#导入工具包并加载数据
#-*- coding: utf-8 -*-
import pandas as pd
import numpy as np
# 可视化
import matplotlib.pyplot as plt
import seaborn as sns
# 机器学习---用于用户流失预测
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score
#plt.rcParams['font.family'] = 'SimHei'
#plt.rcParams['axes.unicode_minus'] = False
#读取数据
dx = pd.read_csv('telecom.csv')
# 查看数据集大小
print(dx.shape)
# 运行结果:(7043, 21)
# 设置查看不省略
##列名与数据对其显示
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
##显示所有列
pd.set_option('display.max_columns', None)
##显示所有行
pd.set_option('display.max_rows', None)
# 查看前5条数据
print(dx.head())
# 查看数据是否存在Null
print(pd.isnull(dx).sum()) # Null计数
# 查看数据类型
print(dx.info())
#dx.dtypes
#dx[['TotalCharges']].astype(float)
#ValueError: could not convert string to float:
#强制转换为数字,不可转换的变为NaN
dx['TotalCharges']=dx['TotalCharges'].apply(pd.to_numeric, errors='coerce')
test=dx.loc[:,'TotalCharges'].value_counts().sort_index()
print(test.sum()) #运行结果:7032
# 查看缺失数据
print(dx.tenure[dx['TotalCharges'].isnull().values==True])
# 统计缺失总数
print((dx.tenure[dx['TotalCharges'].isnull().values==True]).value_counts())
#运行结果:0 11
print(dx.isnull().any())
print(dx[dx['TotalCharges'].isnull().values==True] [['tenure','MonthlyCharges','TotalCharges']])
#将总消费额填充为月消费额
dx.loc[:,'TotalCharges'].replace(to_replace=np.nan,value=dx.loc[:,'MonthlyCharges'],inplace=True)
#查看是否替换成功
print(dx[dx['tenure']==0][['tenure','MonthlyCharges','TotalCharges']])
到这就提示错误ValueError: Series.replace cannot use dict-value and non-None to_replace
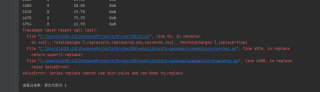
求解
[](链接:
百度网盘 请输入提取码
百度网盘为您提供文件的网络备份、同步和分享服务。空间大、速度快、安全稳固,支持教育网加速,支持手机端。注册使用百度网盘即可享受免费存储空间

提取码:ad39)






