问题遇到的现象和发生背景
为什么下面一个xapth取不到内容返回的是一个空的列表,
但是xpath是正确的啊
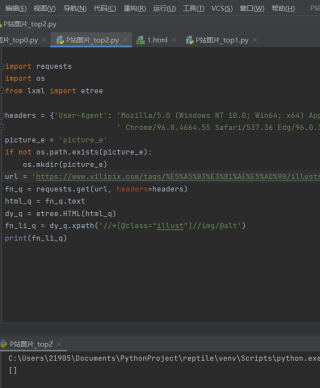

问题相关代码,请勿粘贴截图
import requests
import os
from lxml import etree
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/527.36 (KHTML, like Gecko)'
' Chrome/96.0.8664.55 Safari/537.36 Edg/56.0.054.43'}
picture_e = 'picture_e'
if not os.path.exists(picture_e):
os.mkdir(picture_e)
url = 'https://www.vilipix.com/tags/%E5%A5%B3%E3%81%AE%E5%AD%90/illusts'
fn_q = requests.get(url, headers=headers)
html_q = fn_q.text
dy_q = etree.HTML(html_q)
fn_li_q = dy_q.xpath('//*[@class="illust"]//img/@alt')
print(fn_li_q)
运行结果及报错内容
C:\Users\21905\Documents\PythonProject\reptile\venv\Scripts\python.exe
[]
进程已结束,退出代码为 0
我的解答思路和尝试过的方法
xpath定位我写过几个代码有时候有用有时候没用,感觉就特别玄学。
我想要达到的结果
得到网页图片下的名字