
新手刚接触Python爬虫,本来是为了拿段html代码练习正则表达式,结果输出结果后有空格,想用yield和strip进行去除空格后整理并输出成excel,但是只要一去除空格,顺序就发生变化了,麻烦大神看看是怎么回事吧,感谢!!!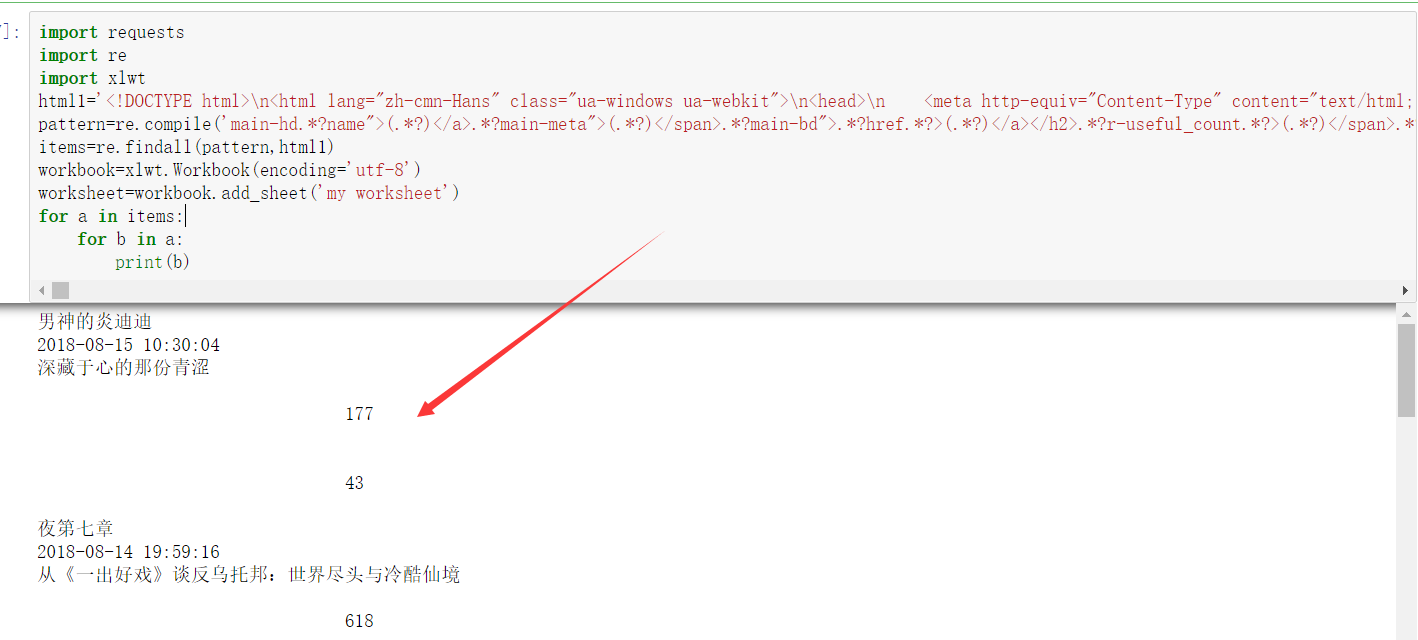
练习用的代码:
import requests,re #获取url
def get_page(url):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
response=requests.get(url,headers=headers)
if response.status_code==200:
return response.text
else:
return none
`
import requests
import re
import xlwt
url='https://movie.douban.com/review/best/?start=0'
html=re.sub(" ","",get_page(url))
pattern=re.compile('main-hd.*?name">(.*?)</a>.*?main-meta">(.*?)</span>.*?main-bd">.*?href.*?>(.*?)</a></h2>.*?r-useful_count.*?>(.*?)</span>.*?r-useless_count.*?>(.*?)</span>',re.S)
items=re.findall(pattern,html1)
workbook=xlwt.Workbook(encoding='utf-8')
worksheet=workbook.add_sheet('my worksheet')
for a in items:
for b in a:
print(b) #结果一:正确顺序
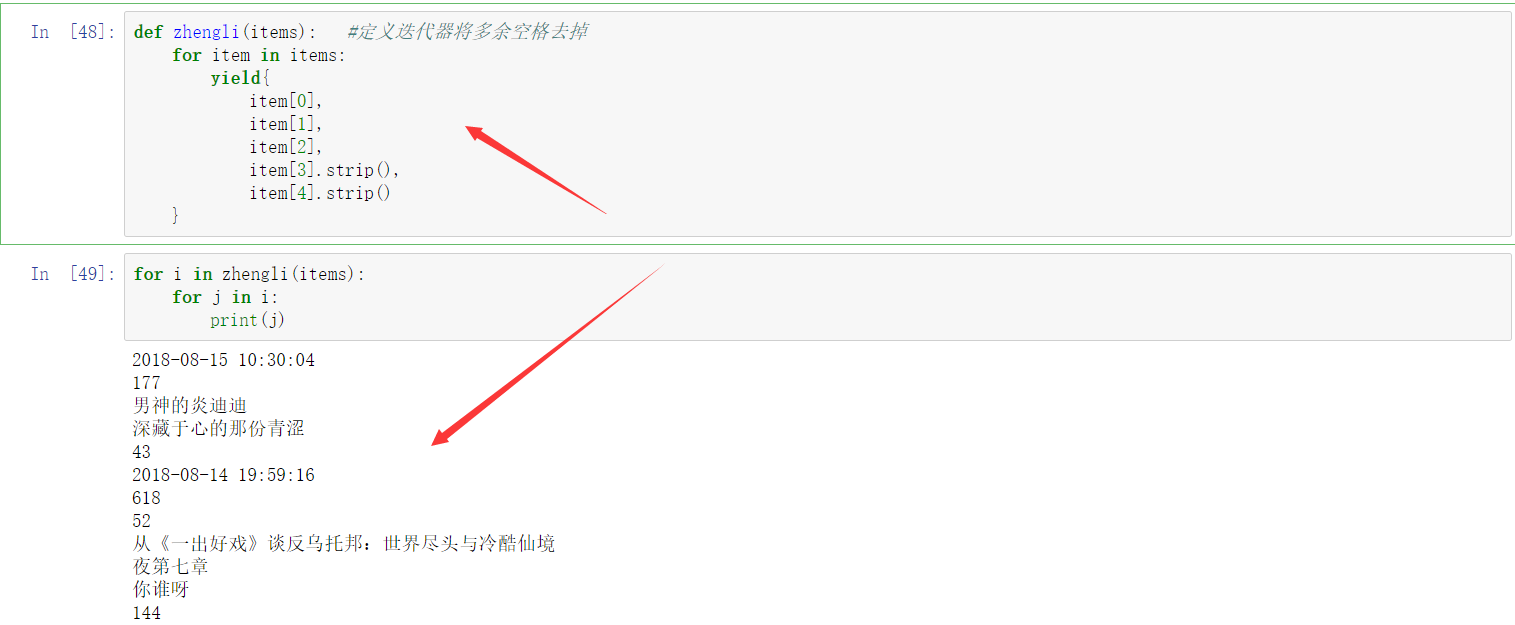
def zhengliA(items): #多余空格去掉
for item in items:
yield{
item[0],
item[1],
item[2],
item[3].strip(), #strip去除前后空格回车
item[4].strip()
}
for i in zhengliA(items):
for j in i:
print(j) #结果二:顺序不对






