
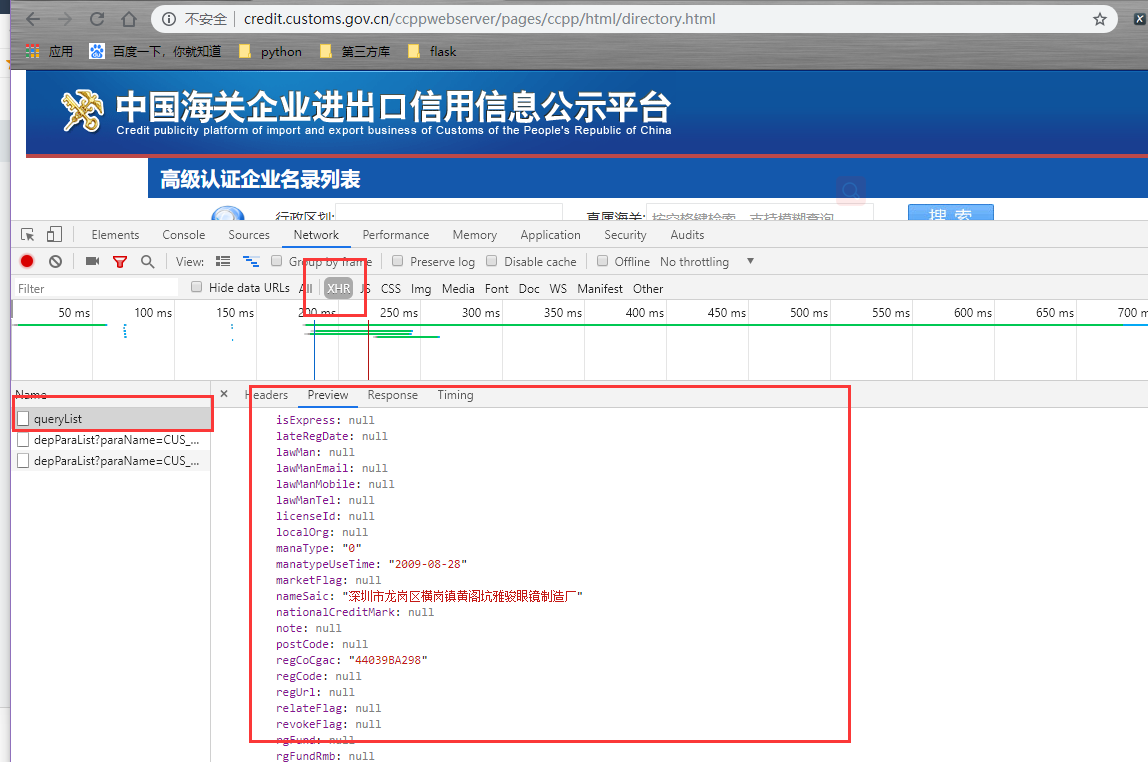
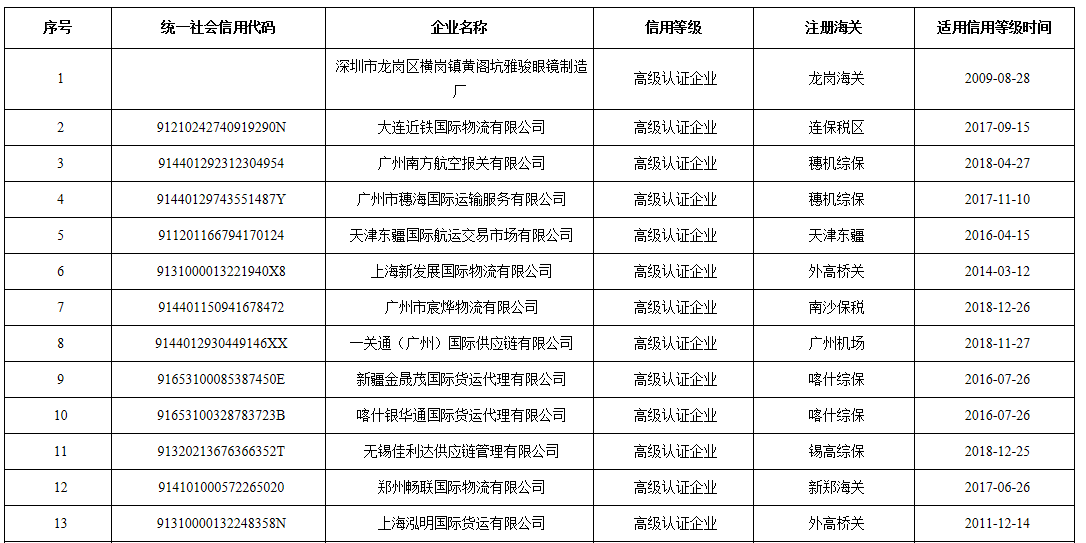
各位大神好,目前是python小白,正自学爬数据,自己要爬取网站表格信息:
http://credit.customs.gov.cn/ccppwebserver/pages/ccpp/html/directory.html
图片说明
代码如下:
import pandas as pd
import csv
for i in range(1,158): # 爬取全部157页数据
url = 'http://credit.customs.gov.cn/ccppwebserver/pages/ccpp/html/directory.html'
tb = pd.read_html(url)[1]
tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)
print('第'+str(i)+'页抓取完成')
但运行完只爬到了表头,请问各位大神哪里出错了?





{kind=link}