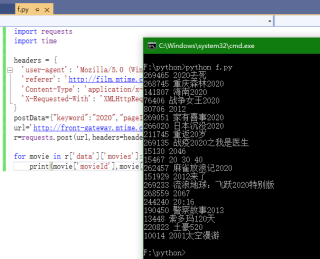
事情是这样的,懵新需要爬:
http://film.mtime.com/search/movies/movies?type=year&word=2020
该网址是Ajax加载的,于是从F12里找到了内容列表的Ajax请求地址,
我添加了headers,试过用post、session、urllib.request和parse,但是输出仍是如下:
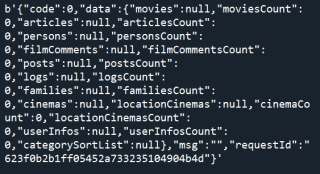
而网页源代码是:
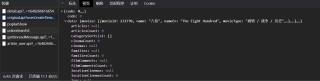
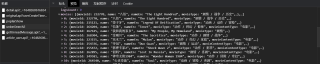
可以看到爬取的结果在 "data":{"movies":null 处缺失了。
求高人帮忙QAQ
另:selenium也尝试过,但不知道为什么爬不出目标代码
我的爬取目标是这个:

以下是我的代码尝试:
'''列表'''
import requests
import time
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.15 Safari/537.36',
'referer': 'http://film.mtime.com/search/movies/movies/',
'Cookie':'_tt_=4C0AFCA656D18084A23E7B6412F25E1B; _mi_=d3a134e125f4fa820a77efdb9d273749; _mu_=74E13B5A06A0337502CB85D0824A4D36; searchHistoryCookie=%u4F60%u597D%u674E%u7115%u82F1; Hm_lvt_07aa95427da600fc217b1133c1e84e5b=1646656056,1647854587,1647913019,1648107725; Hm_lpvt_07aa95427da600fc217b1133c1e84e5b=1648192257',
'Content-Encoding': 'gzip',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'X-Requested-With': 'XMLHttpRequest'
}
year = 2020
params = {
'genreTypes':'' ,
'area':'' ,
'type':'2020',
'pageIndex':'1',
'pageSize':'20',
'searchType':'0',
"locationId":'290',
'keyword': '',
}
url='http://front-gateway.mtime.com/mtime-search/search/unionSearch2'
#遵守robots协议
ROBOTSTXT_OBEY = True
#并发请求个数(越小越慢)
CONCURRENT_REQUESTS = 1
#下载延迟时间(越大请求越慢)
DOWNLOAD_DELAY = 60
#默认False;为True表示启用AUTOTHROTTLE扩展
AUTOTHROTTLE_ENABLED = True
#默认3秒;初始下载延迟时间
AUTOTHROTTLE_START_DELAY = 60
#默认60秒;在高延迟情况下最大的下载延迟
AUTOTHROTTLE_MAX_DELAY = 60
#使用httpscatch缓存
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 1
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
'''
#模拟浏览器爬
from urllib import request, parse
import urllib.request
import urllib.parse
import json
data = urllib.parse.urlencode(params).encode('utf-8')
response = request.Request(url=url, data=data, headers=headers, method='POST')
import ssl# 全局取消证书验证
ssl._create_default_https_context = ssl._create_unverified_context
response = urllib.request.urlopen(response)
print(response.read().decode('utf-8'))
'''
#session会话爬
session = requests.session()
res = session.post(
url=url,
params=params,#json=params也没有目标内容
headers=headers,timeout=None)
print(res.content)