问题遇到的现象和发生背景
做课题由于样本数据较少,需要对一个时间序列数据进行样本扩充,我的想法是先提取时间序列的特征,然后利用特征构造或者还原新的数据。时间序列特征提取利用tsfresh.数据形式及代码如下
提取的特征
数据形式
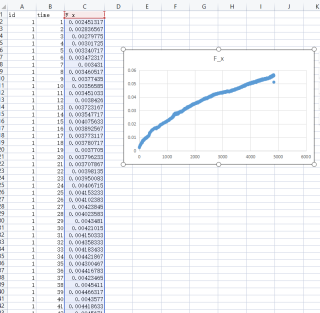
我想要达到的结果
我想知道有没有合适的算法或者方法可以根据时序数据的特征构造新的时序数据或者还原数据,或者不用提取特征可以直接对样本数据进行扩充的方法。不用提供代码,求个大致的方向就可以的

做课题由于样本数据较少,需要对一个时间序列数据进行样本扩充,我的想法是先提取时间序列的特征,然后利用特征构造或者还原新的数据。时间序列特征提取利用tsfresh.数据形式及代码如下
提取的特征
数据形式
我想知道有没有合适的算法或者方法可以根据时序数据的特征构造新的时序数据或者还原数据,或者不用提取特征可以直接对样本数据进行扩充的方法。不用提供代码,求个大致的方向就可以的
 分享
分享
 关注
关注给你一个简单的例子吧
import numpy
def forecast_speed(hour):
x = [1,2,3,5,6,7,8,9,10,12,13,14,15,16,18,19,21,22]
y = [100,90,80,60,60,55,60,65,70,70,75,76,78,79,90,99,99,100]
mymodel = numpy.poly1d(numpy.polyfit(x, y, 3))
myline = numpy.linspace(1, 23, 100)
speed = mymodel(float(hour))
return {'speed':speed}
print(forecast_speed(17))
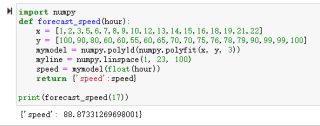
上面这个就是输入一组x和y的数据,拟合了一个函数模型,然后就能输入x返回对应的y值了
更多的内容可以去了解一下机器学习、拟合模型相关的内容
你说说什么叫做规律?什么叫做原样本的特征?特征不就是规律么?你能把这些特征都量化下来么?如果特征无法量化,那如何判断是符合原样本特征呢?如果特征都量化了,那不就是一个函数模型么?
这个例子可不只是一个缺失值,按照这种方式,你可以选择对应的2次函数或更多次函数(即函数图像为曲线),让机器学习自动帮你把各次项系数算出来.
给你个文档先看看吧
机器学习 - 多项式回归
![]() https://www.w3school.com.cn/python/python_ml_polynomial_regression.asp
https://www.w3school.com.cn/python/python_ml_polynomial_regression.asp
分享 系统已结题
4月19日
系统已结题
4月19日 已采纳回答
4月11日
创建了问题
4月10日
已采纳回答
4月11日
创建了问题
4月10日

