
小白一个,刚学python爬虫1天,因为跟朋友夸下海口说简单的都会,但我这个就不会了。
具体需求:python爬取跳页url不变的网页表格数据。
url:http://gs.amac.org.cn/amac-infodisc/res/pof/fund/index.html
爬取表格所有页的数据: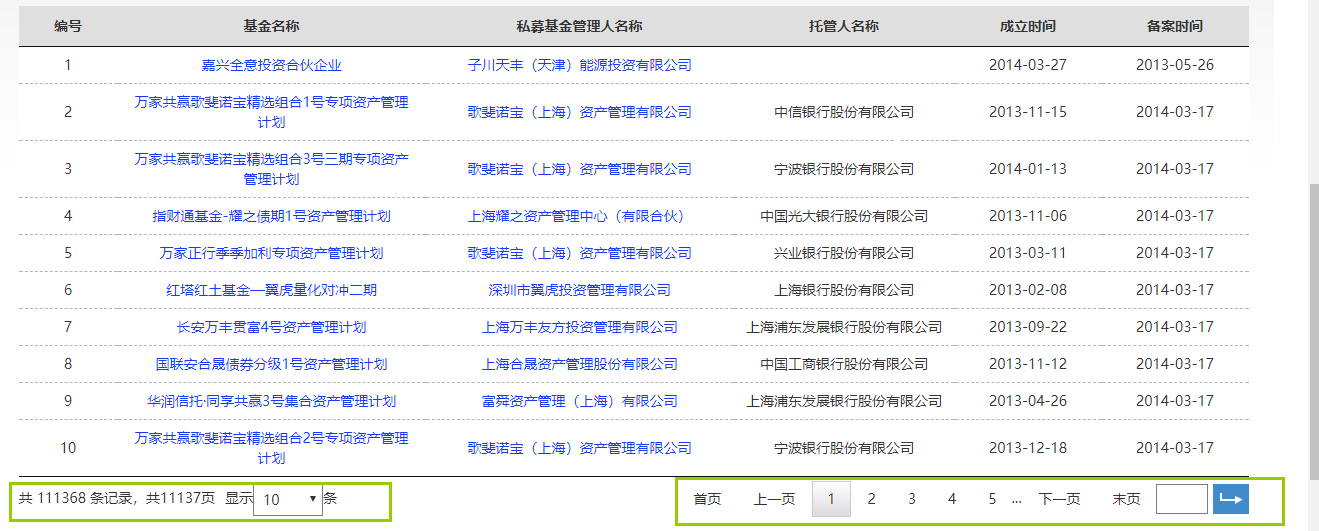
求求大神救救孩纸* _*

python爬取跳页url不变的网页表格数据

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

4条回答 默认 最新

 关注
关注数据量不大的话 用selenium 自动化 ,或者抓包分析接口
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决评论 打赏无用 1举报 分享
- 2023-03-06 15:35网络安全小时光的博客 使用python selenium实现url不变,翻页爬取页面数据
- 2020-12-04 12:52See_sea125的博客 在使用python进行爬取数据时,有时会遇到表格筛选条件变化但上方链接不变化的情况。本文介绍一种简单的方法,爬取数据。 例子为nba-stat网站的 [http://www.stat-nba.com/team/ATL.html] 直接获取到的html文件无法...
- 2020-08-04 20:21西瓜之神�的博客 python爬虫-翻页url不变网页的爬虫探究 url随着翻页改变的爬虫已经有非常多教程啦,这里主要记录一下我对翻页url不变网页的探究过程。 学术菜鸡第一次写CSDN,请大家多多包容~ 如果对你有一点点帮助,请帮我点个赞...
- 2020-12-06 13:23weixin_39587164的博客 python爬虫-翻页url不变网页的爬虫探究url随着翻页改变的爬虫已经有非常多教程啦,这里主要记录一下我对翻页url不变网页的探究过程。学术菜鸡第一次写CSDN,请大家多多包容~ 如果对你有一点点帮助,请帮我点个赞吧...
- 2022-01-10 15:30Python_QB的博客 针对同一个网页,不同的页码,如软科中国大学排名2021,发现随着页码翻动,url未变 通过 F12,进入到网络,Ctrl+F进行搜索一个大学,会发现一个payload.js的文件 打开这个文件,发现数据都存在这个...
- 2025-07-18 15:51Python爬虫项目的博客 本文将详细介绍如何使用Python最新技术组合(Selenium+BeautifulSoup)高效提取网页表格数据。文章包含完整代码示例、异常处理机制、反反爬策略以及数据存储方案,适合中高级Python开发者学习现代网页数据采集技术。...
- 2019-03-29 14:04qq_40800269的博客 该网页上的内容为与脑疾病有关的蛋白质基因等数据,对于跳页后URL变化的网站,可以观察url的变化情况,从而用一个...但目标网页跳页后url未变化,是用了js跳页,针对这种情况,我在查阅资料时了解到有两种方法可...
- 2021-01-22 14:06爬遍天下无敌手的博客 电商时代,淘宝、京东、天猫商品数据对店铺运营有极大的帮助,因此获取相应店铺商品的数据能够带来极大的价值,那么我们如何获取到相应的数据呢? 上一篇我们讲了python打包exe可执行文件: Python打包成exe文件史...
- 2021-09-02 20:57品尚公益团队的博客 完整代码: ...url="https://shenzhen.baixing.com/jiudianfuwu/m35936-m5238/" headers={'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/\ 537.36 (KHTML, like Gecko) Chrome/86.0.4
- 没有解决我的问题, 去提问
