如题,图片如下: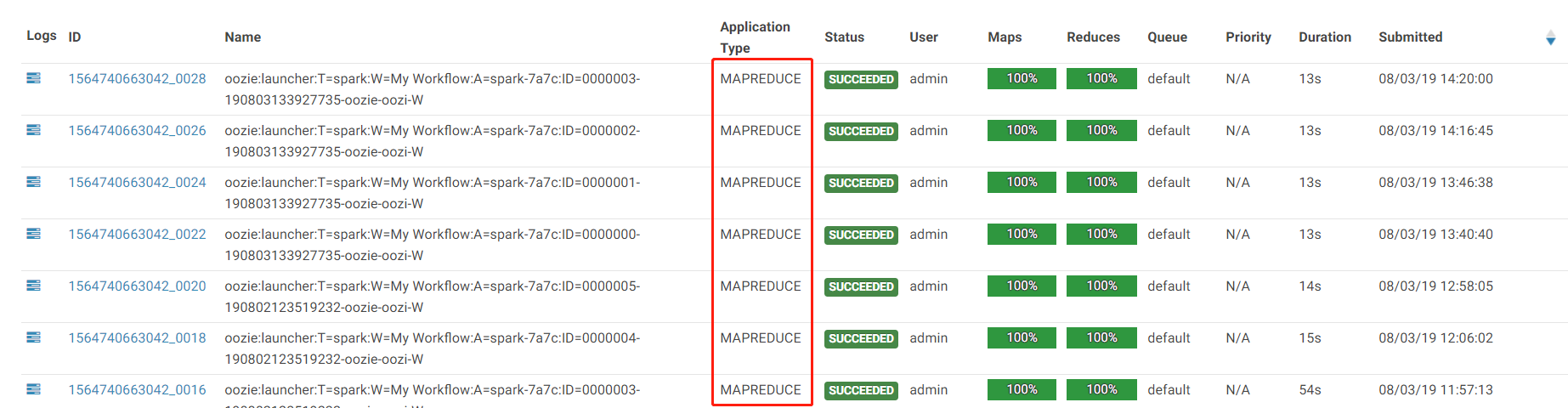

hue上oozie配置spark2,执行任务的时候Application Type不是Spark而是MapReduce

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

- 2021-03-14 15:38weixin_39945445的博客 一、oozie执行shell脚本(执行mr任务,实现合并增量数据)1、点击创建、拖动到上面 2、添加命令:bash,当然也可以是linux的其他可执行的命令 3、添加参数:注意---》参数名称是shell脚本的全称(run-mr-compact.sh) 4、...
- 2019-01-16 17:53weixin_34112208的博客 使用Hue可以方便的通过界面制定Oozie的工作流,支持Hive、Pig、Spark、Java、Sqoop、MapReduce、Shell等等。Spark?那能不能支持Spark2的呢,接下来本文章就主要讲述如何使用Hue创建Spark1和Spark2的Oozie工作流。 ...
- 2018-08-24 09:47XiaoGuang-Xu的博客 一、oozie执行shell脚本(执行mr任务,实现合并增量数据) 参考:http://gethue.com/use-the-shell-action-in-oozie/ 1、点击创建、拖动到上面 2、添加命令:bash,当然也可以是linux的其他可执行的命令 ...
- 2017-07-09 15:31oo寻梦in记的博客 一、oozie执行shell脚本(执行mr任务,实现合并增量数据) 参考:http://gethue.com/use-the-shell-action-in-oozie/ 1、点击创建、拖动到上面 2、添加命令:bash,当然也可以是linux的其他可执行的命令 ...
- 2018-06-26 15:55袁一白的博客 使用Hue可以方便的通过界面制定Oozie的工作流,支持Hive、Pig、Spark、Java、Sqoop、MapReduce、Shell等等。Spark?当让可以,但是自带是spark1的,那能不能支持Spark2的呢?接下来本文章就主要讲述如何使用Hue创建...
- 2019-04-03 17:48黑尾土拨鼠的博客 一、Hive配置 (一)、简介 一般的公司都会有自己的数据仓库,而大多数都选择的Hive数据仓库,总所周知hive默认使用MapReduce来进行数据操作,MapReduce在计算过程中会涉及数量巨大的网络传输,这需要耗费大量...
- 2023-01-13 17:57黑马程序员官方的博客 转存失败重新上传取消在没有工作流调度系统之前,公司里面的任务都是通过于是,出现了一些管理crontab任务的调度系统,如等。而在,现在市面上常用的工作流调度工具有等。由于公司安装CDH集群时已经安装好Oozie,且...
- 2022-06-02 21:24sun_xo的博客 大数据学习笔记之五——《在Oozie中配置 map-reduce workflow》
- 2018-07-01 09:44graphnj的博客 讲个前段时间遇到的问题,项目中用到的spark on yarn基于oozie进行应用的编排调度,oozie支持fork/join机制,就是可以在fork之后可以分出多个分支用于调度其他action,对我们来说就是调用多个spark应用。但遇到的...
- 2020-01-20 18:05·慕晴·的博客 hadoop集群搭建一、 环境说明二、 环境搭建1. Linux系统准备2. 安装jdk8并设置环境变量3. 安装mysql4. 安装hadoop5. 安装hive6. 安装sqoop7. 安装oozie8. 安装hue9. 结果展示10. 启动集群脚本 一、 环境说明 我...
- 2022-08-30 17:14xyc1211的博客 | |- job.properties |- input-data #数据源 |- src job.properties 工作流参数配置 #任务执行路径:hdfs nameNode=hdfs://localhost:8020 examplesRoot=examples #oozie资源存储路径 oozie.wf.application.path=${...
- 2019-02-20 21:43create17的博客 例如操作HDFS上的数据,运行MapReduce Job,执行Hive的SQL语句,浏览HBase数据库,执行Oozie任务等。 该文主要对Hadoop服务的一些配置通过Ambari进行更改,同时也需要修改${HUE_HOME}/desktop/conf...
- 2024-03-07 11:44大数据侠客的博客 在Spark中有两类task,一类是shuffleMapTask,一类是resultTask,第一类task的输出是shuffle所需数据,第二类task的输出是result,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是...
- 2021-01-10 17:30hwq317622817的博客 那么,对于OozieWorkflow中的一个个的action(可以理解成一个个MapReduce任务)Oozie是根据什么来对action的执行时间与执行顺序进行管理调度的呢?答案就是我们在数据结构中常见的有向无环图(DAGDirect Acyclic ...
- 2020-11-26 15:46zxfBdd的博客 2、hue 4.0.0 编译及安装 地址:https://github.com/cloudera/hue/releases/tag/release-4.1.0(也许是发版这弄错了吧,连接是4.1.0,内容版本是4.0.0) 2.1 修改%HUE_CODE_HOME%/hue/maven/pom.xml版本,如下...
- 2020-06-29 11:24BigMoM1573的博客 文章目录1、Oozie的介绍oozie的组件介绍2、oozie的架构3、oozie的安装4、oozie的使用4.1、使用oozie调度shell脚本4.2、使用oozie调度hive4.3、使用oozie调度MR任务4.4、oozie的任务串联4.5、oozie的任务调度,定时...
- 没有解决我的问题, 去提问
