如题:本人依照了标题为 “Python selenium —— 文件下载,不弹出窗口,直接下载到指定路径” 一文 ,学习如何 设置下载不弹窗,然而结果无效
测试的url :'http://sahitest.com/demo/saveAs.htm'
程序代码如下: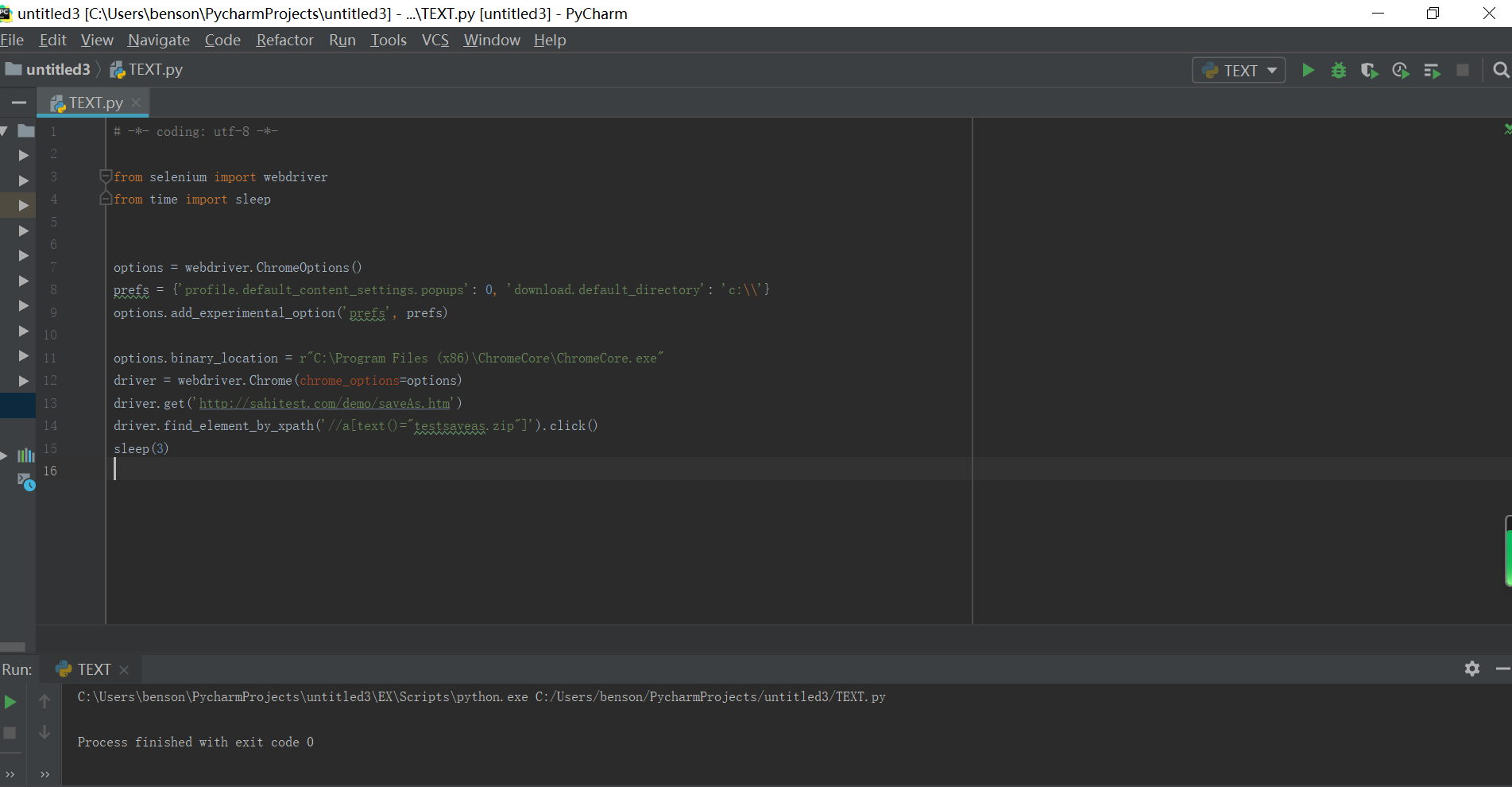
代码没有报错,然而运行代码时,下载文件的窗口依旧弹出,如下图所示: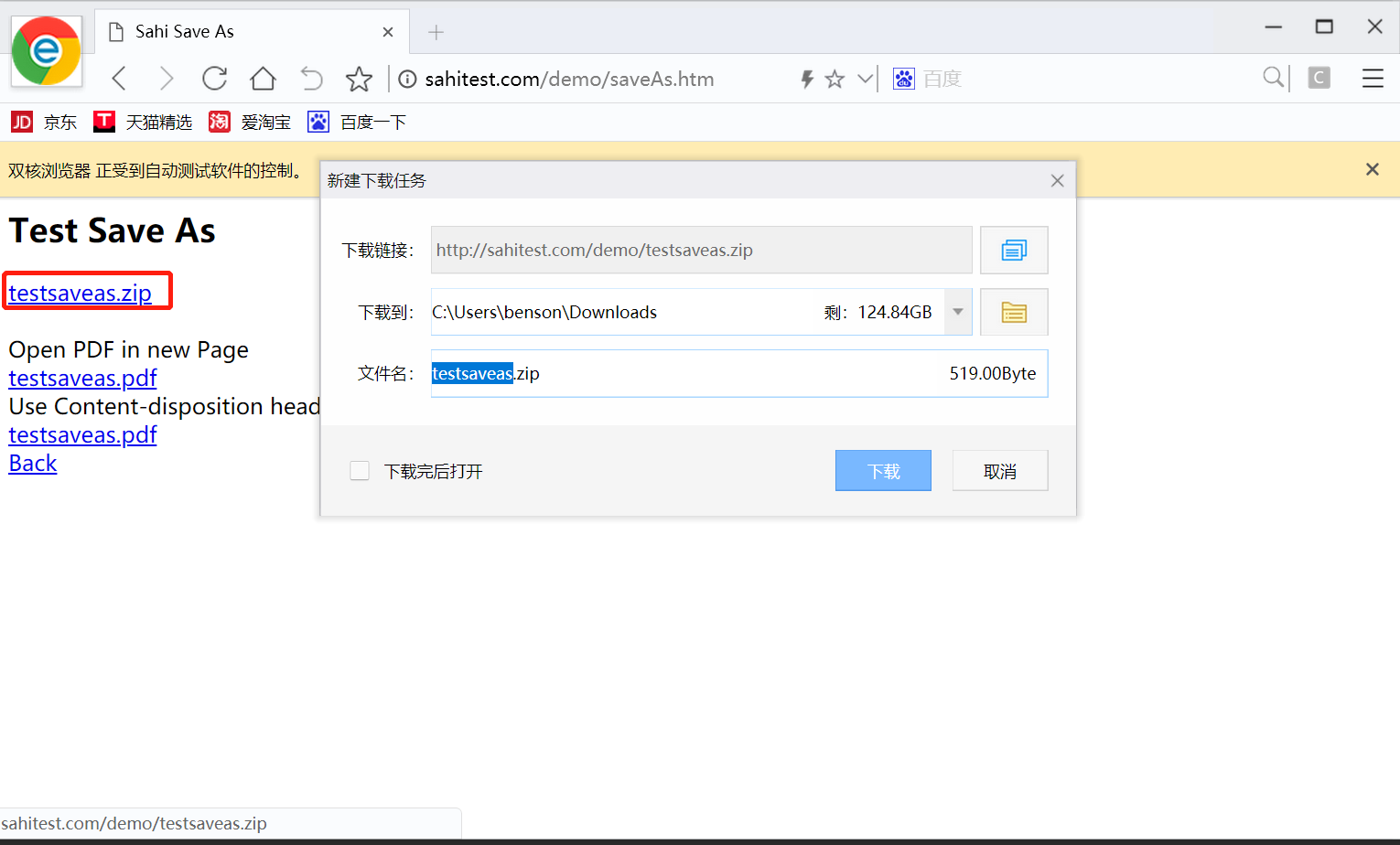
求大虾指导,为什么设置了下载不弹窗以及下载路径后,结果不生效,也不报错,问题出在哪里?

如题:本人依照了标题为 “Python selenium —— 文件下载,不弹出窗口,直接下载到指定路径” 一文 ,学习如何 设置下载不弹窗,然而结果无效
测试的url :'http://sahitest.com/demo/saveAs.htm'
程序代码如下:
代码没有报错,然而运行代码时,下载文件的窗口依旧弹出,如下图所示:
求大虾指导,为什么设置了下载不弹窗以及下载路径后,结果不生效,也不报错,问题出在哪里?
 分享
分享 问题本人已解决,通过多方的查找,本人发现这种方式已经过时了,可能与版本变动有关系,最新的解决方法可以参照以下链接:
https://blog.csdn.net/weixin_41812940/article/details/82423892
分享 已结题
(查看结题原因) 5月6日
已结题
(查看结题原因) 5月6日

