

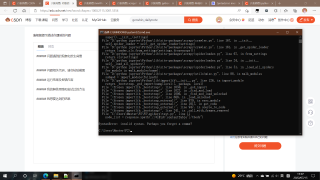
运行报错,有点搞不清楚是哪错了,求解答,提供斯路,学习学习,谢谢
!
import scrapy
from P2.items import P2Item
class TestSpider(scrapy.Spider):
name = 'test'
allowed_domains = ['zb.yfb.qianlima.com']
start_urls = ['http://zb.yfb.qianlima.com/yfbsemsite/mesinfo/zbpglist']
def parse(self, response):
node_list = response.xpath("//*[@id="contentTable"]/tbody")
items=[]
for node in node_list:
item = P2Item()
time = node.xpath("./td[1]/text()").extract()
place = node.xpath("./td[2]/text()").extract()
title = node.xpath("./td[4]/a/text()").extract()
item['time'] = name[0]
item['place'] = title[0]
item['title'] = info[0]
items.append(item)
return items
#pass
这是代码
尝试该过网页抓取的xpath的语句不对
我想要达到的结果
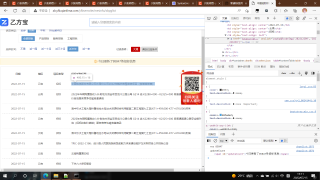
最后我想达到的效果是
日期 状态 项目名称
这样的一个文件








