
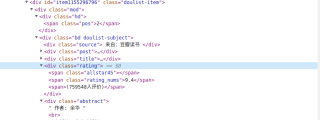
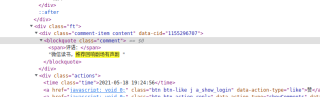
请问各位,用xpath提取评语(比如图片中标黄的:微信读书,推荐回想剧场有声响)怎么提取呀,本来(759548人评价)也不会的后来百度解决了,这第二个问题实在不会,麻烦各位优秀的程序员(媛)解答谢谢,谢谢
结果

"""
豆瓣图书top250数据抓取-lxml+xpath
"""
import requests
from lxml import etree
import time
import random
from fake_useragent import UserAgent
class DoubanBookSpider:
def __init__(self):
self.url='https://www.douban.com/doulist/139873963/?start={}'
def get_html(self,url):
"""请求函数-获取html"""
headers={"User-Agent":UserAgent().random}
html=requests.get(url=url,headers=headers).content.decode('utf-8','ignore')
# 直接调用解析函数
self.parse_html(html)
def parse_html(self, html):
"""解析函数-解析提取数据"""
parse=etree.HTML(html)
table_list=parse.xpath('//div[@class="article"]')
for table in table_list:
item={}
# item["name"]=table.xpath('.//div[@class="title"]/a/text()')
# # print(item["name"])
# item["comment"]=table.xpath('.//div[@class="abstract"]/text()')
# # print(item["comment"])
# item["score"]=table.xpath('.//span[@class="rating_nums"]/text()')
# # print(item["score"])
# item["number"]=table.xpath('.//div[@class="rating"]/span/text()')
# # print(item["number"])
# item["instructions"] = table.xpath('.//blockquote[@class="comment"]/text()')
# # print(item["instructions"])
# print(item)
# 书的名称
name_list=table.xpath('.//div[@class="title"]/a/text()')
item["name"]=name_list[0].strip() if name_list else None
# 以上相当于x=3 if 5>2 else 8
# 书的描述
comment_list=table.xpath('.//div[@class="abstract"]/text()')
item["comment"] = comment_list[0].strip() if name_list else None
# 书的评分
comment_list=table.xpath('.//span[@class="rating_nums"]/text()')
item["score"] = comment_list[0].strip() if name_list else None
# 评论人数
number_list=table.xpath('.//div[@class="rating"]/span[count(@*)=0]/text()')
item["number"]= number_list[2].strip() if name_list else None
# 评语
instructions_list = table.xpath('.//blockquote[@class="comment"]/span/text()')
item["instructions"]= instructions_list[0].strip() if name_list else None
print(item)
def run(self):
for page in range(1,11):
start=(page-1)*25
page_url=self.url.format(start)
self.get_html(url=page_url)
# 控制数据抓取的频率
time.sleep(random.uniform(0,2))
if __name__ == '__main__':
spider=DoubanBookSpider()
spider.run()







