import requests
from lxml import etree
import time
创建类对象
class Tieba_spider(object):
def int(self,BaiduTie,start_page,end_page):
self.base_url="http://tieba.baidu.com"
self.headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
#开始页
self.start=start_page
self.end=end_page
self.name=BaiduTie
# 第一层数据解析 找到贴吧的对应链接地址
self.first_xpath='//div[@class="t_con cleafix"]/div/div/div/a/@href'
# 第二层数据解析 找到对应网址下所有的图片
self.sec_xpath='//img[@class="BDE_Image"]/@src'
# 发送请求
def send_request(self,url,params={}):
time.sleep(1)
try:
# 携带参数和头部请求地址
response=requests.get(url,params=params,headers=self.headers)
# 返回请求页面内容
return response.content
except Exception:
print("程序异常")
def write_file(self,data,page):
print(page)
filename="TieBa"+page
with open(filename,"wb") as f:
f.write(data)
# 解析数据
def analysis_data(self,data,xpathstr):
html_data=etree.HTML(data)
# 取出所有的指定标签内容
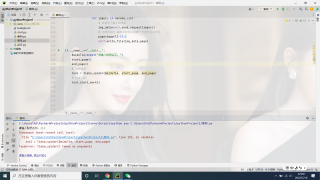
data_list=html_data.xapth(xpathstr)
return data_list
# 开始调用
def start_work(self):
for page in range(self.start,self.end+1):
pn=(page-1)*50
params={"kw":self.name,"pn":pn,"fr":"search"}
# 发送第一次页面请求
first_data=self.send_request(self.base_url+'/f?',params)
first_data_list=self.analysis_data(first_data,self.first_xpath)
# 将每一条的数据请求
for link in first_data_list:
# 拼接请求地址
link_url=self.base_url+link
# 请求每个href里面的页面
secode_data=self.send_request(link_url)
# 二次解析 去取每个帖子里面的图片 地址 请求数据
secode_list=self.analysis_data(secode_data,self.sec_xpath)
print(secode_list)
for imgurl in secode_list:
# 请求每个图片的内容
img_data = self.send_request(imgurl)
# 字符串切片 截取字符串末尾15个字符作为文件名
page = imgurl[-15:]
self.write_file(img_data, page)
if name=="main":
BaiduTie=input("请输入贴吧名字:")
start_page=1
end_page=1
# 实例化类
tool = Tieba_spider(BaiduTie, start_page, end_page)
# 调度方法
tool.start_work()