
问题遇到的现象和发生背景
准确率太低,且变化不大
问题相关代码,请勿粘贴截图
# -*- coding: utf-8 -*-
from torchvision import datasets,transforms
import torchvision
from torch.utils.data import DataLoader
import torch
from torch import nn
import matplotlib.pyplot as plt
import receive_image
import torch.optim as optim
import numpy as np
#基本配置
#device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
batch_size = 16
lr = 1e-4
epochs = 20
#数据读入
image_size = 128
data_transform = transforms.Compose([
#transforms.ToPILImage(),
transforms.Resize(image_size),
transforms.ToTensor()
])
receive_image.receiveImage()
train_path = 'D:\identify\data\data0-z_image'
train_data = datasets.ImageFolder(train_path,transform=data_transform)
val_path = 'D:\identify\data\data0-z_image_val'
val_data = datasets.ImageFolder(val_path,transform=data_transform)
train_loader = torch.utils.data.DataLoader(train_data,batch_size = batch_size,shuffle = True,drop_last = True)
val_loader = torch.utils.data.DataLoader(val_data,batch_size = batch_size,shuffle = False)
images,lables = next(iter(train_loader))
'''
#查看数据
print(images.shape,lables.shape)
plt.imshow(images[0][0])
'''
#模型构建
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3,32,5),
nn.ReLU(),
nn.MaxPool2d(2,stride = 2),
nn.Dropout(0.3),
nn.Conv2d(32,64,5),
nn.ReLU(),
nn.MaxPool2d(2,stride = 2),
nn.Dropout(0.3)
)
self.fc = nn.Sequential(
nn.Linear(64*29*45,512),
nn.ReLU(),
nn.Linear(512,36)
)
def forward(self,x):
#print(x.shape)
x = self.conv(x)
#print(x.shape)
x = x.view(-1,64*29*45)
x = self.fc(x)
return x
model =Net()
#model = model.cuda()
#设置损失函数
criterion = nn.CrossEntropyLoss()#交叉熵损失函数
#设定优化器(Adam优化器)
optimizer = optim.Adam(model.parameters(),lr = 0.000001)
#训练和测试
def train(epoch):
model.train()
train_loss = 0
for data,lable in train_loader:
#data,lable = data.cuda(),lable.cuda()
#print(data,lable)
optimizer.zero_grad() #优化器梯度置零
output = model(data) #将data送入模型训练
#print(output,lable)
loss = criterion(output,lable) #计算损失函数
loss.backward() #将loss反向传播回网络
optimizer.step() #使用优化器更新模型参数
train_loss += loss.item()*data.size(0)#注意要乘以batchsize
#print(train_loss)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch:{}\tTrain_loss:{:.6f}'.format(epoch,train_loss))
def val(epoch):
model.eval()
val_loss = 0
get_lables = []
pred_lables = []
with torch.no_grad():
for data,lable in val_loader:
output = model(data)
#print(output)
#print(lable)
pred = torch.argmax(output,1)
#print(pred)
get_lables.append(lable.cpu().data.numpy())
pred_lables.append(pred.cpu().data.numpy())
loss = criterion(output,lable)
val_loss += loss.item()*data.size(0)
val_loss = val_loss/len(val_loader.dataset)
#print(get_lables,pred_lables)
get_lables,pred_lables = np.concatenate(get_lables),np.concatenate(pred_lables)
acc = np.sum(get_lables==pred_lables)/len(pred_lables)
print('Epoch:{} \tValidation Loss:{:.6f},Accuracy:{:6f}'.format(epoch,val_loss,acc))
for epoch in range(1,epochs+1):
train(epoch)
val(epoch)
运行结果及报错内容
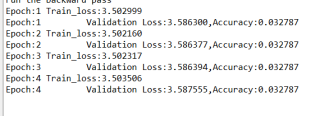
我的解答思路和尝试过的方法
每种类别字母或者数字只有20个,是不是因为样本数目太少,导致准确率太低?或者是其他原因
我想要达到的结果
提高识别率








