
图一:
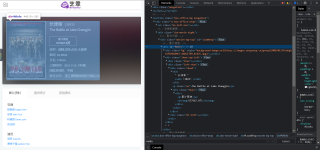
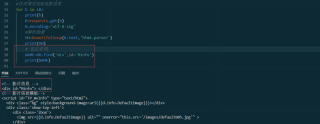
图一是网络我想爬取的定位内容,名字票房都在'div'id名为MInfo的标签中。图二是我用python代码打印出来的关于这个网站的解析结果,发现影片信息'div'id名为MInfo的标签是空的,我打印出来也是None。这是为什么?
图二:

图一:
图二:
 分享
分享
soup = BeautifulSoup(B.text,'html.parser')
如果还是不行的话那就右键查看源码看一下 是否是这个id
分享 系统已结题
2月24日
系统已结题
2月24日 已采纳回答
2月16日
创建了问题
9月18日
已采纳回答
2月16日
创建了问题
9月18日




