
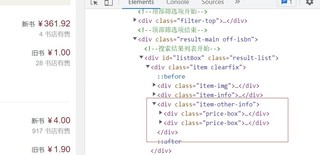
想要爬取新书一列并保存到csv中,用pyquery
它在相同的div中,而且还有空缺值,没有新书的值为空

 分享
分享
from pyquery import PyQuery as pq
import requests
import csv
url='https://item.kongfz.com/Cxiaoshuo/w{}/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'}
alldata=[['书名','价格','新书价格','旧书价格','作者','出版社','出版日期','装订']]
for i in range(99,100):#采集第99页,没有新书
newurl=url.format(i)
html=requests.get(newurl,headers=headers).text
doc=pq(html)
items=doc('#listBox .item').items()
for item in items:
book=pq(item.html())
title=list(book('.title a').items())[0].text()
attrs=list(book('.zl-isbn-info').items())[0].text().split('/')
price=attrs[-1].strip()
pricebox=list(book('.price-info a').items())
newprice=""
oldprice=""
if len(pricebox)>1:#有新书和旧书
newprice=pricebox[0].text().replace("新书","").strip()
oldprice=pricebox[1].text().replace("旧书","").strip()
else:#只有新书或者旧书其中一种
s=pricebox[0].text()
if '新书' in s:
newprice=s.replace("新书","").strip()
else:
oldprice=s.replace("旧书","").strip()
alldata.append([title,price,newprice,oldprice,attrs[0],attrs[1],attrs[2],attrs[3]])
#有特殊字符串,需要用utf-8编码,不指定编码会出错,但是Excel打开utf-8编码csv会乱码。需要自己记事本打开另存为ansi编码的csv文件
with open('item.kongfz.com.csv','w',newline='',encoding='utf-8')as f:
writer = csv.writer(f)
for data in alldata:
writer.writerow(data)
 系统已结题
10月27日
系统已结题
10月27日 已采纳回答
10月19日
创建了问题
10月19日
已采纳回答
10月19日
创建了问题
10月19日


