
matlab实现下面编码:
香农编码存在的的不足主要是香农编码方法由于在编码过程中以码字的码长作为先决条件而没有考虑各个码字之间的相关性,这就导致了编码结果会出现很大的冗余,往往编码效率很低。比如某个码字编码为111,但由于香农编码规则事先规定了该码字的先定码长为6,因此该码字的码长就必须为6。显而易见,由于对码长的限制,会导致码字的平均码长变大,从而降低了编码效率。
针对上面的缺点,本文通过如下的优化算法对香农编码效率进行提高和改善。
优化算法原理是首先忽略码字的码长限定,只根据最小概率来计算其对应的码长l,接着以此为参考,计算出所有累加概率对应的二进制串,并对二进制串的长度作出规定,即规定所有的二进制串的长度均为l,然后从每个长度为l的二进制串中选择符合原则的码字,码字选取的原则是任意一个码字一定不是前后备用码的前缀,同时码字的选择必须要从二进制串的最左端开始。从左往右依次选取。具体步骤如下:
(1)将信源符号按照递减顺序降序排列;
(2)计算概率最小符号的对数值,;
(3)计算出第j个符号的累加概率;
(4)将每个符号对应的累加概率进行二进制转换,取小数点后面的j位作为备用码;
(5)选取符号所对应的码字原则为:
码字的选取从概率最大的符号对应的备用码的第一个二进制位开始,从前往后依次选取;
码字的选取不能是前后备用码的前缀,而且每个码字的选取应尽可能短。
结果显示编码效率以及编码结果,最好能对比传统的香农编码和改进的香农编码的运行时间

matlab算法实现改进的香农编码

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

7条回答 默认 最新
 CodeBytes 2023-03-12 20:10关注
CodeBytes 2023-03-12 20:10关注该回答引用ChatGPT
如有疑问,可以回复我!
运行结果
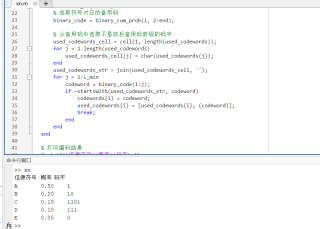
代码如下:
% 定义信源符号及其对应的概率 source = ['A', 'B', 'C', 'D', 'E']; prob = [0.5, 0.2, 0.15, 0.1, 0.05]; % 首先按照递减顺序对信源符号进行排序 [sorted_prob, index] = sort(prob, 'descend'); sorted_source = source(index); % 计算最小概率对应的码长 L_min = ceil(log2(1/sorted_prob(end))); % 计算每个符号对应的累加概率 cum_prob = cumsum(sorted_prob); % 将每个符号的累加概率转换成二进制串,取小数点后 L_min 位作为备用码 binary_cum_prob = dec2bin(round(cum_prob * 2^L_min), L_min+1); % 为每个符号选取码字 codewords = cell(size(source)); used_codewords = cell(size(source)); for i = 1:length(source) % 选取符号对应的备用码 binary_code = binary_cum_prob(i, 2:end); % 从备用码中选取不是前后备用码前缀的码字 used_codewords_cell = cell(1, length(used_codewords)); for j = 1:length(used_codewords) used_codewords_cell{j} = char(used_codewords{j}); end used_codewords_str = join(used_codewords_cell, ''); for j = 1:L_min codeword = binary_code(1:j); if ~startsWith(used_codewords_str, codeword) codewords{i} = codeword; used_codewords{i} = [used_codewords{i}, {codeword}]; break; end end end % 打印编码结果 fprintf('信源符号\t概率\t码字\n'); for i = 1:length(source) fprintf('%c\t\t%.2f\t%s\n', sorted_source(i), sorted_prob(i), codewords{i}); end本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2022-11-04 20:56香农编码的 MATLAB 语言实现是指使用 MATLAB 编程语言来实现香农编码算法的过程。 香农编码的 MATLAB 语言实现可以分为四个步骤:首先,给定信源符号概率,然后判断信源符号概率是否满足概率分布。如果不满足概率...
- 2022-09-08 21:25阿里matlab建模师的博客 此程序缺点是,第一个码字都是以0开始,因为对累加概率求二进制后,小数点后的数都是0,取几位由码长确定,而香农编码是不唯一的,如果手动编码就不存在这样的问题。其次,对信源符号概率进行从小到大的排序,以便...
- 2024-12-27 14:03二分香农编码的MATLAB实现,不仅涉及到算法的编程实现,还包括对算法效率和压缩效果的评估。通常需要通过实验和分析来确定算法在不同数据集上的性能表现,并对算法进行优化,以适应不同的应用场景。 二分香农编码...
- 2021-04-22 11:33这个项目似乎是一个使用MATLAB实现香农编码的实例,它允许用户输入自定义变量,以便于理解和应用编码过程。下面我们将深入探讨香农编码的基本原理以及如何用MATLAB进行实现。 **香农编码原理:** 香农编码由美国...
- 2024-04-01 10:51三种经典信源编码方式 香农编码,费诺编码,霍夫曼编码的Matlab函数实现
- Infor_Theory_AHU的博客 信源编码的Matlab实现:费诺编码、香农编码、哈夫曼编码、算术编码、LZ编码、连续信源编码量化简介
- 2021-12-11 08:51誓言随青春一笑了之的博客 % L -- 平均码长 str -- 符号序列 P -- 概率 % code -- 编码 l -- 二分区间下界 r -- 二分区间上界 function L = fun_Shannon(str, P, code, l, r, L) if l == r fprintf("%c : %s\n", str(l), code); L = L + ...
- 2021-04-23 10:56weixin_39994665的博客 信息论与编码实验报告 院系: 哈尔滨理工大学荣成校区 专业: ...四、实验环境 Microsoft Windows 7 Matlab 6.5 五、编码程序计算如下信源进行香农编码,并计算编码效率: X P a0 0.2 a1 0.19 a2 0.18 a3 0.17 a4 0......
- 2025-07-28 17:48Matlab实现的LDPC译码算法可以直接模拟硬件实现的过程,通过Matlab的硬件描述语言(HDL)生成器可以直接输出硬件描述语言代码,以便在FPGA上实现。在Matlab环境下实现算法不仅可以对算法进行验证,还可以通过MATLAB ...
- 2024-11-22 09:48基于Matlab实现LDPC编码是一项涉及编码理论、数字信号处理和计算机编程等多方面知识的复杂任务。通过实践这种任务,不仅可以加深对LDPC编码的理解,而且能够提升在Matlab环境下的编程能力和问题解决能力。
- 2021-06-26 12:05整个流程非常清晰,逐步深入地将香农编码的算法实现出来。 此外,文章还通过两个具体的离散信源模型的香农编码结果的比较,来说明编码效率的差异。通过比较可以发现,编码效率与信源符号的概率分布有关。在特定条件...
- 2021-10-16 02:043. 香农编码的MATLAB实现:提供具体的MATLAB代码示例,演示如何在MATLAB环境中实现香农编码算法,包括符号频率统计、码字生成和编码过程。 4. 结果展示和交互操作:介绍如何在GUI中展示编码结果,以及用户如何通过...
- 2024-04-26 10:07学习和使用这个MATLAB实现源码,可以帮助你深入理解信道编码的基本原理,熟悉编码算法的实现步骤,同时通过实际操作提升编程技能。如果你是通信工程、电子工程或相关专业的学生,或者是从事通信系统研发的工程师,这...
- 2025-01-05 12:13而“Polar_master.zip”文件可能包含了实际的Polar编码和解码算法的MATLAB源代码和可能的C语言实现,这些文件是进行算法测试和评估的关键资源。 因此,这个压缩包是研究Polar编码和解码的重要资料库,它不仅包含了...
- 2023-04-02 22:18tongxinbanyungong的博客 在研究改进后的费诺码时,我发现在很多情况下改进后的费诺码的编码效率和霍夫曼码的编码效率相同,但是我仔细分析后两者还是有本质区别的,改进的费诺码是在费诺码的基础上进行的本质依然是均分概率,而霍夫曼码是多...
- 2024-05-04 10:25本资源提供了一个使用MATLAB实现的LDPC译码算法,特别针对码长960、码率0.5的配置,而且这个实现完全模拟了FPGA(Field-Programmable Gate Array)硬件实现的语言和量化处理。接下来,我们将详细探讨这些关键知识点...
- 2025-08-14 11:50而Matlab作为一种高级数学计算和仿真软件,提供了强大的编程环境和丰富的工具箱,非常适合用于实现算法原型,进行算法效果的验证和分析。 本项目的开发基于Matlab平台,不仅要求实现上述编码算法和简单加密解密算法...
- 2021-03-26 09:30总之,Polar码在MATLAB中的实现涉及到信道极化理论、生成矩阵构造、编码解码算法的编程以及性能评估等多个方面,通过理解这些核心概念,可以深入掌握Polar码的工作原理,并利用MATLAB进行实际应用开发。
- 2021-09-29 01:163. **编码实现**:MATLAB可以实现香农编码算法,包括建立符号与码字的映射关系、编码过程以及解码过程。通过编写自定义函数,如`shannon_encoding()`和`shannon_decoding()`,学生能够直观地理解编码和解码的逻辑。 ...
- 没有解决我的问题, 去提问


问题事件
 已结题
(查看结题原因) 3月16日
已结题
(查看结题原因) 3月16日-
已采纳回答
3月16日
-
赞助了问题酬金20元
3月12日
-
创建了问题
3月12日