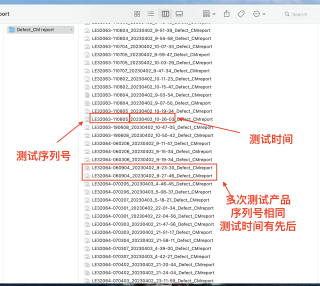
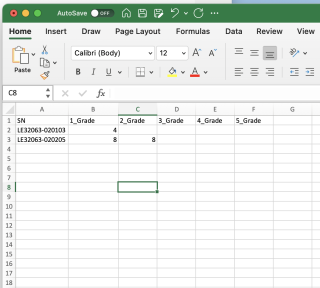
占坑答题,先答复你的第一个小目标,每天搞一个小目标,按照统一的时间的格式来对文件名进行操作,假设source文件夹下有几个csv的文件,以下是代码片段:
import os
folder_path = '..\source' # 文件夹路径 可以使用相对路径也可以使用绝对路径
for filename in os.listdir(folder_path):
name, ext = os.path.splitext(filename)
if ext == '.csv':
time_str = name.split('_')[2] # 获取时间字符串
h, m, s = time_str.split('-') # 分割小时、分钟和秒
new_time_str = f'{h.zfill(2)}-{m.zfill(2)}-{s.zfill(2)}' # 构造新的时间字符串
new_name = name.replace(time_str, new_time_str) + ext # 构造新的文件名
os.rename(os.path.join(folder_path, filename), os.path.join(folder_path, new_name))


向第二个目标进发:
假设你的python的工程文件夹下有两个文件夹,一个是source,一个target,其中target的文件夹是什么都没有的,source文件夹下的内容如下:

现在要实现你的第二需求,代码片段如下:
import os
import shutil
from datetime import datetime
source_folder = 'source' # 源文件夹
target_folder = 'target' # 目标文件夹
latest_files = {} # 每个 SN 对应的最新文件
# 实现目标1,统一格式
for filename in os.listdir(source_folder): # 文件夹路径,使用相对路径
name, ext = os.path.splitext(filename)
if ext == '.csv':
time_str = name.split('_')[2] # 获取时间字符串
h, m, s = time_str.split('-') # 分割小时、分钟和秒
new_time_str = f'{h.zfill(2)}-{m.zfill(2)}-{s.zfill(2)}' # 构造新的时间字符串
new_name = name.replace(time_str, new_time_str) + ext # 构造新的文件名
os.rename(os.path.join(source_folder, filename), os.path.join(source_folder, new_name))
# 实现目标2,文件搬运
# 遍历源文件夹中的所有文件
for file_name in os.listdir(source_folder):
sn = file_name.split('_')[0] # 获取文件名中的 SN
time_str = file_name.split('_')[1] + '_' + file_name.split('_')[2] # 获取文件名中的时间字符串
time = datetime.strptime(time_str, '%Y%m%d_%H-%M-%S') # 将时间字符串转换为 datetime 对象
if sn not in latest_files or time > latest_files[sn][1]: # 如果当前 SN 还没有对应的最新文件,或者当前文件的时间比已知的最新时间更晚
latest_files[sn] = (file_name, time) # 更新最新文件和最新时间
# 遍历每个 SN 对应的最新文件
for sn, (latest_file, latest_time) in latest_files.items():
shutil.copy(f'{source_folder}/{latest_file}', f'{target_folder}/{latest_file}') # 拷贝最新文件到目标文件夹中
运行之后:
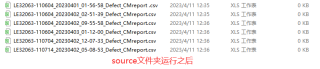

第三天来实现需求3,全部代码如下:
import os
import shutil
import csv
from datetime import datetime
from collections import defaultdict
source_folder = 'source' # 源文件夹
target_folder = 'target' # 目标文件夹
latest_files = {} # 每个 SN 对应的最新文件
# 实现目标1,统一格式
for filename in os.listdir(source_folder): # 文件夹路径,使用相对路径
name, ext = os.path.splitext(filename)
if ext == '.csv':
time_str = name.split('_')[2] # 获取时间字符串
h, m, s = time_str.split('-') # 分割小时、分钟和秒
new_time_str = f'{h.zfill(2)}-{m.zfill(2)}-{s.zfill(2)}' # 构造新的时间字符串
new_name = name.replace(time_str, new_time_str) + ext # 构造新的文件名
os.rename(os.path.join(source_folder, filename), os.path.join(source_folder, new_name))
# 实现目标2,文件搬运
# 遍历源文件夹中的所有文件
for file_name in os.listdir(source_folder):
sn = file_name.split('_')[0] # 获取文件名中的 SN
time_str = file_name.split('_')[1] + '_' + file_name.split('_')[2] # 获取文件名中的时间字符串
time = datetime.strptime(time_str, '%Y%m%d_%H-%M-%S') # 将时间字符串转换为 datetime 对象
if sn not in latest_files or time > latest_files[sn][1]: # 如果当前 SN 还没有对应的最新文件,或者当前文件的时间比已知的最新时间更晚
latest_files[sn] = (file_name, time) # 更新最新文件和最新时间
# 遍历每个 SN 对应的最新文件
for sn, (latest_file, latest_time) in latest_files.items():
shutil.copy(f'{source_folder}/{latest_file}', f'{target_folder}/{latest_file}') # 拷贝最新文件到目标文件夹中
# 实现目标3,实现文件内容摘取
# 创建一个字典来存储每个SerialNumber的Panel_Grade值
serialnumber_panelgrade = defaultdict(list)
# 获取文件夹中的所有文件名
filenames = os.listdir(target_folder)
# 遍历文件夹中的每个csv文件
for filename in filenames:
if filename.endswith('.csv'):
with open(os.path.join(target_folder, filename), newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
serialnumber = row['SerialNumber']
panel_grade = row['Panel_Grade']
if panel_grade:
serialnumber_panelgrade[serialnumber].append(panel_grade)
# 创建一个新的csv文件
with open('./target/summary.csv', 'w', newline='') as csvfile:
fieldnames = ['SerialNumber', 'Panel_Grade_test1', 'Panel_Grade_test2', 'Panel_Grade_test3', 'Panel_Grade_test4']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for serialnumber, panel_grades in serialnumber_panelgrade.items():
row = {'SerialNumber': serialnumber}
for i in range(1, 5):
if i <= len(panel_grades):
row[f'Panel_Grade_test{i}'] = panel_grades[i-1]
else:
row[f'Panel_Grade_test{i}'] = 0
writer.writerow(row)
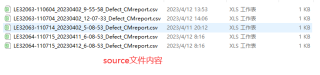
target文件夹:
运行结果: