
想问一下爬虫出现list index out of range怎么解决?li标签中有空值
报错如下
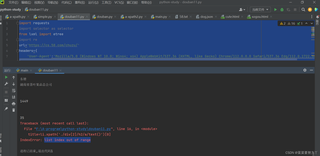
原始界面中有广告,使得中间存在空值
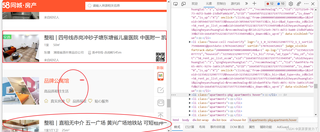
爬取的数据类型如下:

代码如下
import requests
import selector as selector
from lxml import etree
import re
url='https://cs.58.com/chuzu/'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.58'
}
page_text=requests.get(url=url, headers=headers).text
tree=etree.HTML(page_text)
li_list=tree.xpath('//ul[@class="house-list"]/li')
fp=open('58.txt','w',encoding='utf-8')
i=0
for li in li_list:
title=li.xpath('./div[2]/h2/a/text()')[0]
print(title)
fp.write(title+' ')
room_type=li.xpath('./div[2]/p[@class="room"]/text()')[0]
fp.write(room_type + ' ')
print(room_type)
# location1 = li.xpath('./div[2]/p[@class="room"]/text()')[0]
location1 = li.xpath('./div[2]/p[@class="infor"]/a/text()')[0]
fp.write(location1 + ' ')
print(location1)
location2 = li.xpath('./div[2]/p[@class="infor"]/a/text()')[1]
fp.write(location2 + ' ')
print(location2)
position = li.xpath('./div[2]/p[@class="infor"]/text()')[0]
fp.write(position + ' ')
print(position)
money = li.xpath('./div[3]/div[2]/b[@class="strongbox"]/text()')[0]
fp.write(money + ' ')
print(money)
buy = li.xpath('./div[3]/div[2]/text()')[0]
fp.write(buy + '\n')
print(buy)
i=i+1
print(i)






