文本聚类效果不理想,数据处理方面:去除了停用词、特殊符号、对文本数据去重、加载了用户词典;算法使用了tf-idf,用kmeans和dbscan来进行聚类,用手肘图确定k值确定不了,用轮廓系数来确定的,第四轮廓系数又太小才有0.006088746097507285。dbscan算法跑的聚类直接就只有一类。我这还有可以优化的吗?应该怎么处理效果太差了
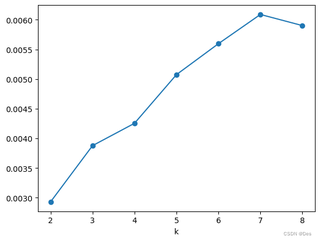
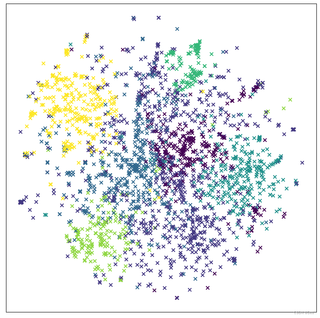
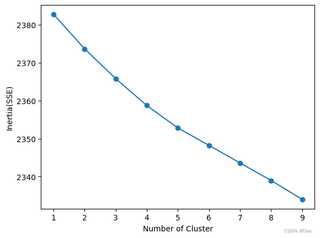

文本聚类效果不理想,数据处理方面:去除了停用词、特殊符号、对文本数据去重、加载了用户词典;算法使用了tf-idf,用kmeans和dbscan来进行聚类,用手肘图确定k值确定不了,用轮廓系数来确定的,第四轮廓系数又太小才有0.006088746097507285。dbscan算法跑的聚类直接就只有一类。我这还有可以优化的吗?应该怎么处理效果太差了
 分享
分享
 关注
关注让阿豪来帮你解答,本回答参考chatgpt3.5编写提供,如果还有疑问可以评论或留言首先,从手肘图中可以看出,数据的聚类效果不是很理想,无法明显地确定最优的k值。其次,从kmeans聚类效果图中可以看到,聚类后的结果并不明显,难以划分成清晰的类别。最后,轮廓系数较低,说明聚类结果不够紧密,存在一定的误差。 对于文本聚类效果不理想的情况,可以尝试以下优化方案:
预处理阶段:
算法优化阶段:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import AgglomerativeClustering
import numpy as np
# 读取文本数据,将每个文件的内容存放到texts列表中
texts = []
with open("data.txt", "r", encoding="utf8") as f:
for line in f:
texts.append(line.strip())
# 将文本数据转换成向量表示
vectorizer = TfidfVectorizer(stop_words="english")
X = vectorizer.fit_transform(texts)
# 构建层次聚类模型
model = AgglomerativeClustering(n_clusters=None, distance_threshold=0.5)
model.fit(X.toarray())
# 获取层次聚类结果
labels = model.labels_
# 输出每个类别的数量
for i in range(len(np.unique(labels))):
print("Cluster %d: %d samples" % (i, np.sum(labels == i)))
该代码读取文本数据,使用tf-idf进行文本编码,然后构建层次聚类模型,最终输出每个类别的数量。可以根据需要调整聚类参数,获取更好的聚类结果。
分享 系统已结题
3月27日
系统已结题
3月27日 创建了问题
3月19日
创建了问题
3月19日

