
问题:编写爬虫时,使用selenium碰到一个问题,不使用代理ip时是可以打开网站的,但是使用代理ip时会打不开网站,网站会显示“无法访问该网站”
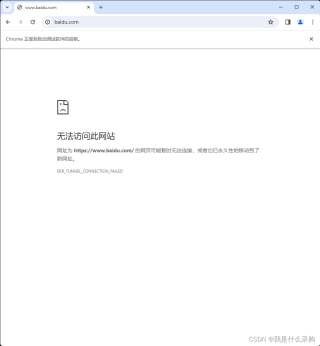
附上代码:
from selenium import webdriver
chromeOptions = webdriver.ChromeOptions()
chromeOptions.add_argument('--proxy-server=http://221.6.139.190:9002')
chromeOptions.add_argument(
'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36')
driver=webdriver.Chrome(chrome_options=chromeOptions)
driver.get('https://blog.csdn.net/zise_xingkong/article/details/112350327')
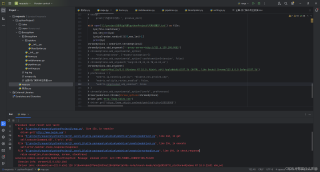
因为我是代理ip都是从免费代理ip网站上爬取得到的,所以我尝试确定是不是代理ip失效导致的。因此,我使用了requests库爬取了同样的网站,但是可以拿到内容。
附上代码:
header={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'}
res=requests.get('https://blog.csdn.net/zise_xingkong/article/details/112350327',proxies={"http":"http://221.6.139.190:9002"},headers=header)
print(res.text)
print(res.status_code)
想请教一下各位,具体问题是出现在哪里?






