如题,tensorflow-gpu跑训练时,Windows的任务管理器显示GPU的compute0使用率90%多,compute1使用率却为0%,截图如下,请问是什么原因?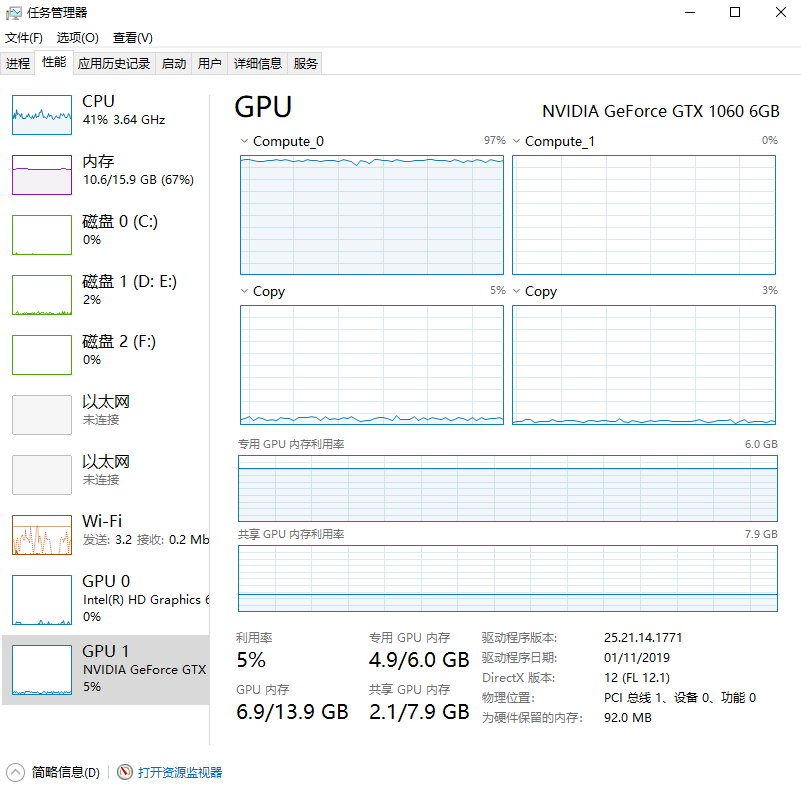

tensorflow-gpu跑训练时GPU的compute0使用率90%多,compute1使用率却为0%

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

4条回答 默认 最新
 threenewbee 2019-09-22 18:57关注
threenewbee 2019-09-22 18:57关注这是很正常的,gpu窗口里面compute0、compute1等表示不同的指令,不是像多cpu那样表示不同的内核,所以一个满的,另一个空的是很正常的。
评论 打赏解决 3无用举报 分享
- 2021-04-20 01:17Potato_Shy的博客 最近用bert训练模型时,发现GPU资源占用很小,小到连bert模型都装不下,然后cpu几乎占满 排除了代码问题,数据传输问题,排除了资源选择问题,懵逼了。。。一时也不知道咋回事,之前还没有遇到过。 2.问题发现 无意...
- 2025-12-16 13:34FasterThanMind的博客 记录在Ubuntu系统中通过conda成功配置tensorflow-gpu的完整流程,重点解决CUDA、cuDNN依赖问题,对比pip安装常见错误,强调使用conda管理环境和依赖的稳定性,避免因版本不匹配导致GPU无法调用。
- 2025-12-16 13:29Hsmiau的博客 详解在Linux系统中通过Anaconda搭建TensorFlow-GPU环境的完整流程,涵盖CUDA与cuDNN的安装配置要点,强调版本兼容性问题及常见错误处理方法,适合深度学习初学者参考。
- 2025-12-16 13:33叶深深的博客 详细介绍TensorFlow-GPU的两种安装方法,包括使用pip直接升级和通过清华镜像下载whl文件离线安装,涵盖版本控制、虚拟环境配置及CUDA兼容性测试,确保顺利启用GPU加速。
- 2025-12-26 14:27黄涵奕的博客 通过检测GPU设备和日志信息确认TensorFlow-GPU是否正常工作,分享在Win10环境下安装CUDA 9、cuDNN 7.0与TensorFlow-gpu 1.10时的典型问题与解决方案,避免版本不匹配导致的GPU识别失败。
- 2023-12-16 21:47孝正123的博客 Win11极速安装Tensorflow-gpu+CUDA+cudnn(含视频链接)
- 2019-03-02 14:59Techblog of HaoWANG的博客 TensorFlow—gpu使用方法(1) TensorFlow—gpu使用方法(2) A.定量设置显存 B. 按需设置显存 实测: 软硬件: GTX1063 CUDA9.1 TensorFlow-gpu Pycharm python3.6 TensorFlow-gpu信息 i...
- 2025-12-16 13:29胡说先森的博客 详细讲解Python+TensorFlow-GPU+CUDA+cudnn与显卡驱动的完整配置流程,涵盖版本匹配、驱动安装、CUDA与cudnn部署及最终GPU可用性测试,助你高效搭建深度学习开发环境。
- 2025-12-26 14:32被ldy取笑的博客 通过检测GPU设备信息验证TensorFlow-GPU是否安装成功,结合CUDA 9、cuDNN 7.0和tensorflow-gpu 1.10.0版本适配经验,解决常见环境配置问题。使用device_lib列出本地设备可清晰确认GPU识别情况,避免因版本不兼容导致...
- 2025-12-16 13:33孟园香的博客 本文详细介绍了在Windows环境下基于Python 3.8配置TensorFlow-GPU的全过程,涵盖CUDA与cuDNN版本匹配、驱动安装、环境变量设置及虚拟环境创建。通过实际测试的版本组合(TF 2.4.4 + CUDA 11.0 + cuDNN 8.2.4),确保...
- 2020-02-28 10:18qq_643582002的博客 查看所使用的tensorflow是GPU还是CPU版本 激活tensorflow环境,在python环境中输入: import os from tensorflow.python.client import device_lib os.environ["TF_CPP_MIN_LOG_LEVEL"] = "99" if __name__ == "_...
- 2021-08-30 10:30甜辣uu的博客 GPU:本机中的GPU编号(有多块显卡的时候,从0开始编号)图上GPU的编号是:0 Fan:风扇转速(0%-100%),N/A表示没有风扇 Name:GPU类型,图上GPU的类型是:Tesla T4 Temp:GPU的温度(GPU温度过高...
- 2019-08-24 15:39cici_iii的博客 一、查看tensorflow是否使用了GPU进行计算 import tensorflow as tf sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) 运行程序,日志若包含 gpu 信息,则使用了 gpu。 ...
- 2018-08-09 15:49米小凡的博客 大家在训练数据的时候,经常会遇到tensorflow会占用发现的所有GPU的情况,这样会影响其他人使用GPU,因此我们可以在使用时设定选用的GPU。 import os os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID...
- 2025-07-25 17:30狗雄的博客 CUDA(Compute Unified Device Architecture)是由NVIDIA推出的一种并行计算平台和编程模型。它允许开发者直接使用NVIDIA的GPU(图形处理单元)进行通用计算,而不仅仅是图形渲染。通过CUDA,开发者能够利用GPU的高...
- 2025-12-26 14:37Kingston Chang的博客 详解在Windows 10系统中配置TensorFlow-GPU 2.2.0的完整流程,涵盖CUDA 10.2与cuDNN的安装、环境变量设置、Anaconda虚拟环境创建及常见问题解决,如缺少cudart64_101.dll的应对方法,确保GPU顺利调用。
- 2025-12-26 14:30次元妹妹的博客 本文详细介绍在Windows 10系统下基于Anaconda配置TensorFlow-GPU环境的完整流程,涵盖显卡驱动、CUDA与cuDNN版本匹配逻辑及安装步骤,帮助用户充分利用GPU进行深度学习训练,避免常见版本冲突问题。
- 2025-12-16 13:28CodeMystic的博客 详细讲解如何配置Anaconda环境,安装适配的CUDA Toolkit 11.2与cuDNN 8.1+,并成功部署TensorFlow-GPU 2.5的过程,解决常见DLL缺失问题,确保GPU可用性测试通过。
- 没有解决我的问题, 去提问
