
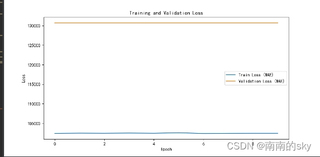
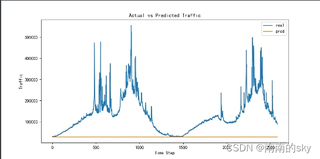
我使用pytorch的LSTM模型预测单变量时,训练集上的loss几乎不下降,验证集的loss每个epoch都一样,最后的预测结果也是呈现一条曲线,但是我找不到问题在哪,loss曲线、预测拟合和代码如下:
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
from sklearn.metrics import mean_absolute_error, mean_squared_error
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler, StandardScaler
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决汉字显示为指定默认字体为黑体
plt.rcParams['axes.unicode_minus'] = False
#加载文件
file = "D:\\Files\\Jupyter Files\\dataSet\\merged_data.csv"
data = pd.read_csv(file)
#参数设置
input_window = 12
output_window = 12
batch_size = 32
train_ratio = 0.6 # 60% 用于训练
val_ratio = 0.2
test_ratio = 0.2
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据集定义
class TrafficDataset(Dataset):
def __init__(self, data, input_window, output_window):
self.data = data
self.input_window = input_window
self.output_window = output_window
def __len__(self):
return len(self.data) - self.input_window - self.output_window + 1
def __getitem__(self, idx):
x = self.data[idx:idx + self.input_window]
y = self.data[idx + self.input_window:idx + self.input_window + self.output_window]
return torch.tensor(x, dtype=torch.float32).to(device), torch.tensor(y, dtype=torch.float32).to(device)
# 数据划分
traffic_data = data['traffic'].values
train_size = int(len(traffic_data) * train_ratio)
val_size = int(val_ratio * len(traffic_data))
test_size = len(traffic_data) - train_size - val_size
train_data = traffic_data[:train_size]
val_data = traffic_data[train_size:train_size+val_size]
test_data = traffic_data[train_size+val_size:]
#数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
train_data = scaler.fit_transform(train_data.reshape(-1, 1))
val_data = scaler.transform(val_data.reshape(-1, 1))
test_data = scaler.transform(test_data.reshape(-1, 1))
train_dataset = TrafficDataset(train_data.reshape(-1), input_window, output_window)
val_dataset = TrafficDataset(val_data.reshape(-1), input_window, output_window)
test_dataset = TrafficDataset(test_data.reshape(-1), input_window, output_window)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# LSTM 模型定义
class LSTMPredictor(nn.Module):
def __init__(self, input_dim=1, hidden_dim=32, output_dim=1, num_layers=2):
super(LSTMPredictor, self).__init__()
self.num_layers = num_layers
self.hidden_dim = hidden_dim
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
self.linear1 = nn.Linear(hidden_dim, hidden_dim)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim)
lstm_out, _ = self.lstm(x, (h0, c0))
output = self.linear2(self.relu(self.linear1(lstm_out[:,-1,:])))
return output
model = LSTMPredictor(input_dim=1, hidden_dim=64, output_dim=output_window).to(device)
criterion = nn.L1Loss() #MAE
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练和验证
train_loss, val_loss = [], []
for epoch in range(10):
model.train()
running_loss = 0.0
for x, y in train_loader:
x = x.unsqueeze(-1)
optimizer.zero_grad()
output = model(x)
# 反归一化预测和真实值
output_denorm = scaler.inverse_transform(output.detach().numpy())
y_denorm = scaler.inverse_transform(y.detach().numpy())
# 转换回 PyTorch 张量,确保计算损失时不带梯度追踪
# 计算反归一化后的损失
loss = criterion(torch.tensor(output_denorm, requires_grad=True), torch.tensor(y_denorm, requires_grad=True))
# loss = criterion(output, y)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss.append(running_loss / len(train_loader))
# 验证
model.eval()
val_running_loss = 0.0
with torch.no_grad():
for x, y in val_loader:
x = x.unsqueeze(-1)
output = model(x)
# 反归一化预测和真实值
output_denorm = scaler.inverse_transform(output.detach().numpy())
y_denorm = scaler.inverse_transform(y.detach().numpy())
# 转换为无梯度的 PyTorch 张量
loss = criterion(torch.tensor(output_denorm), torch.tensor(y_denorm))
# loss = criterion(output, y)
val_running_loss += loss.item()
val_loss.append(val_running_loss / len(val_loader))
print(f'Epoch {epoch + 1}, Train Loss: {train_loss[-1]:.4f}, Val Loss: {val_loss[-1]:.4f}')
# 训练和验证集上的损失曲线
plt.figure(figsize=(10, 5))
plt.plot(train_loss, label='Train Loss (MAE)')
plt.plot(val_loss, label='Validation Loss (MAE)')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
predictions, actuals = [], []
model.eval()
with torch.no_grad():
for x, y in test_loader:
x = x.unsqueeze(-1)
output = model(x)
predictions.append(output.detach().numpy())
actuals.append(y.detach().numpy())
pred = np.concatenate(predictions, axis=0)
real = np.concatenate(actuals, axis=0)
# 反归一化
preds = scaler.inverse_transform(pred)
reals = scaler.inverse_transform(real)
# 计算评估指标
mae = mean_absolute_error(reals, preds)
rmse = np.sqrt(mean_squared_error(reals, preds))
mape = np.mean(np.abs((np.array(reals) - np.array(preds)) / np.array(reals))) * 100
print(f'MAE: {mae:.4f}, RMSE: {rmse:.4f}, MAPE: {mape:.4f}%')
# 预测结果拟合图
plt.figure(figsize=(10, 5))
plt.plot(np.array(reals)[:,0], label='real')
plt.plot(np.array(preds)[:,0], label='pred')
plt.xlabel('Time Step')
plt.ylabel('Traffic')
plt.title('Actual vs Predicted Traffic')
plt.legend()
plt.show()






