python3 最近要通过python实现搜索文件中的关键词出现次数的功能,定义输入的关键字字符串为word="",代码从docx文件读取编码为"utf-8",然后进行匹配搜索。目前输入word="1",word="0"都会报错,word="1234"就不会报错,分析大概是**编码问题**导致的。总的来说,我希望检索“0”这个字符串在某个word文档中出现的次数;是需要从word加载的内容全部转为unicode或者utf-8编码再匹配查找吗?目前“0”会在循环的某个判断停掉 :if i.find(word) != -1:,关于在匹配关键词时用什么编码这块比较小白,希望大神可以帮忙看下:
# -*- coding: UTF-8 -*-
from docx import Document
import re, chardet
filename = "D:\python测试\科目四.docx"
word = "米".encode(encoding='utf-8')
#打开文档
document = Document(filename)
print (filename)
#读取每段资料
l = [paragraph.text.encode(encoding='utf-8', errors='ignore') for paragraph in document.paragraphs]
count = 0
count_2 = 0
j = 0
for i in l:
i = i.strip()
if i.find(word) != -1:
count = count + 1
j = j + 1
print('-', count, '-', i.decode('utf-8'))
print("计数: ", j)
count_2 = count_2 + j
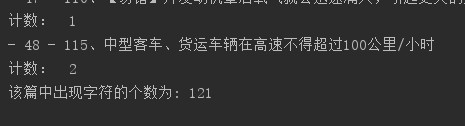
print("该篇中出现字符的个数为:", count_2)
每次报错不一样,有时就是直接循环结束但最后一个print没有执行,也没有任何报错,和输入word参数有关:
如果把编码全部去掉,大部分输入没问题,但是当word="0"时最后一个print没输出,这个如何解释
############################
刚才又改了下,如果加try就会运行正确,不加try就不打印最后一个print: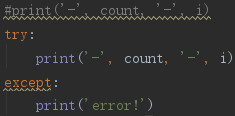
如下是正确的输出: