使用GNN图神经网络深度学习时,GPU显存占满,,但是GPU“利用率只有2%。运算速度慢。我试着用云服务器4卡4090去跑,发现显存占满,但是GPU利用率一个时2%,其余三是0。也试过云服务器1卡4090跑,比在自己电脑上跑还要慢一点
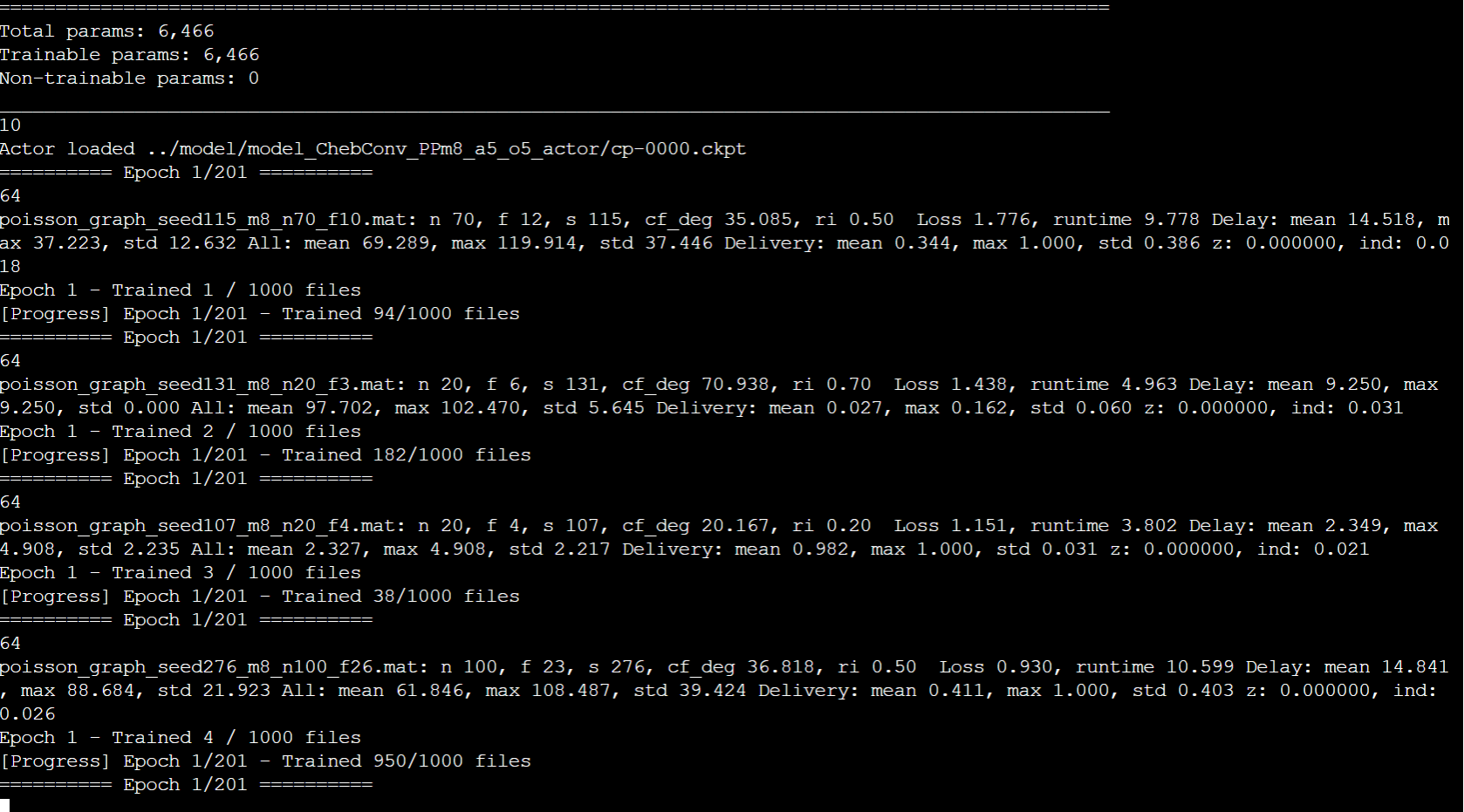
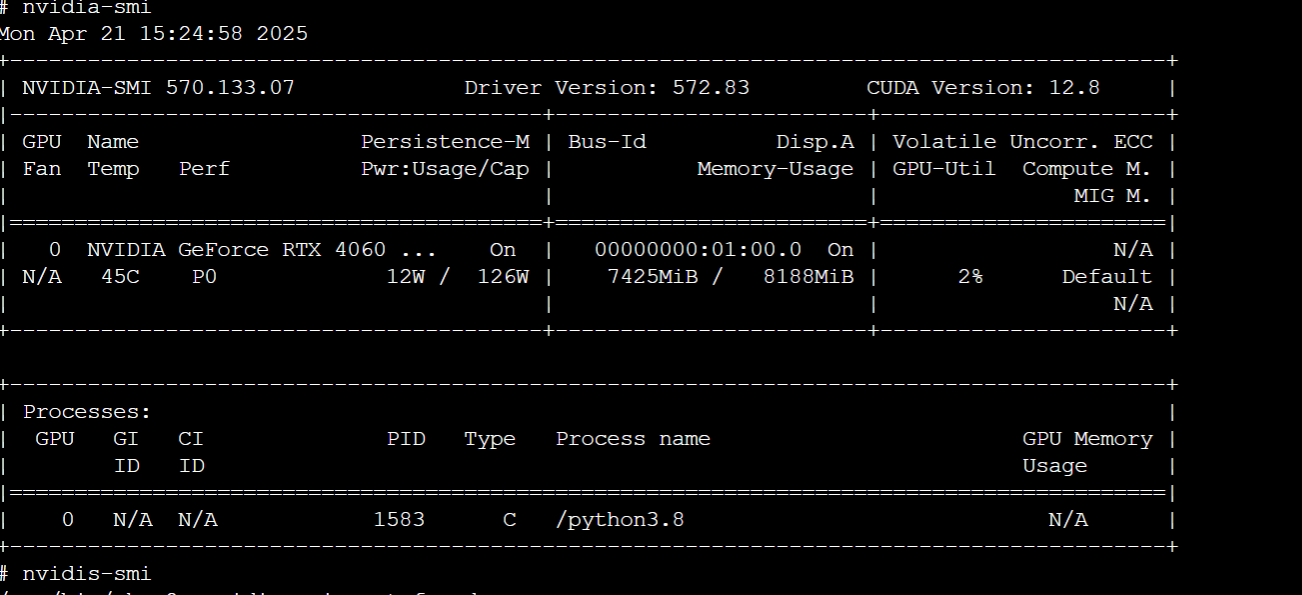
这种情况可能出现的问题在哪呢

使用GNN图神经网络深度学习时,GPU显存占满,,但是GPU“利用率只有2%。运算速度慢。我试着用云服务器4卡4090去跑,发现显存占满,但是GPU利用率一个时2%,其余三是0。也试过云服务器1卡4090跑,比在自己电脑上跑还要慢一点
 分享
分享
 关注
关注让 “紫雾凌寒” 来帮你回答,本回答结合 DeepSeek
如果还有问题,请评论或点击头像私信,如果有帮助到您, 请关注、采纳、点赞
解决方案:
- 检查数据加载与预处理:
DataLoader)的prefetch_factor参数来预取数据,减少数据加载的时间。例如:python
from torch.utils.data import DataLoader
train_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, prefetch_factor=2)multiprocessing库:def preprocess_data(data):
# 数据预处理操作
return processed_data
pool = multiprocessing.Pool(processes=num_processes)
preprocessed_data = pool.map(preprocess_data, raw_data)
pool.close()
pool.join()
- **优化模型计算**:
- 检查模型的计算逻辑,确保没有不必要的重复计算或低效的操作。例如,避免在循环中进行重复的张量创建或计算。
- 对于图神经网络,检查消息传递和聚合操作是否进行了有效的优化。例如,在PyTorch Geometric中,可以使用高效的稀疏矩阵操作来加速图卷积。
- 尝试使用更高效的图神经网络实现,有些库针对特定的硬件进行了优化。比如DGL(Deep Graph Library)在GPU上有较好的性能表现。
- **多卡使用优化**:
- 确保模型在多卡上进行了正确的并行化。在PyTorch中,可以使用`nn.DataParallel`或`DistributedDataParallel`。
- `nn.DataParallel`示例:python
from torch.nn.parallel import DataParallel
model = Model()
device = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
if torch.cuda.device_count() > 1:
model = DataParallel(model)
model.to(device)
- `DistributedDataParallel`示例(需要初始化分布式环境):python
import torch
import torch.distributed as dist
import torch.nn.parallel as nnparallel
dist.init_process_group(backend='nccl')
rank = dist.get_rank()
device = torch.device("cuda:%d" % rank)
model = Model()
model.to(device)
model = nnparallel.DistributedDataParallel(model, device_ids=[rank], output_device=rank)
```
希望以上解答对您有所帮助。如果您有任何疑问,欢迎在评论区提出。
分享 已结题
(查看结题原因) 11月11日
创建了问题
4月22日
已结题
(查看结题原因) 11月11日
创建了问题
4月22日

