
遇到LSTM输入特征维度与输入层维度不一致的问题。
代码最后面三个函数分别是形成特征矩阵函数、lstm样本函数、划分训练集、测试集的函数。
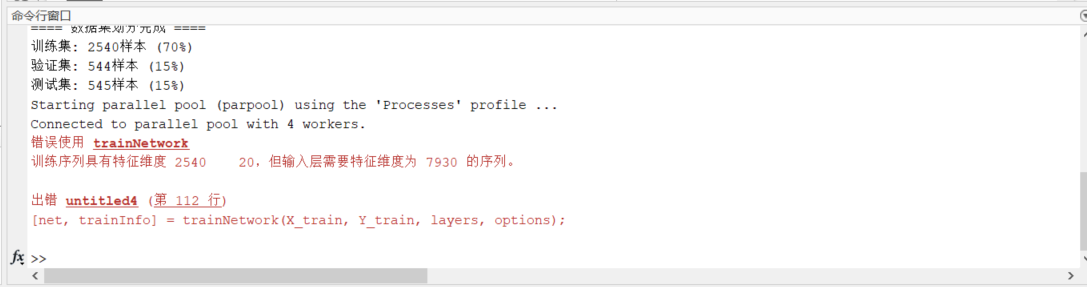
报错如下:
错误使用 trainNetwork
训练序列具有特征维度 2540 20,但输入层需要特征维度为 7930 的序列。
出错 untitled4 (第 112 行)
[net, trainInfo] = trainNetwork(X_train, Y_train, layers, options);
报错截图:
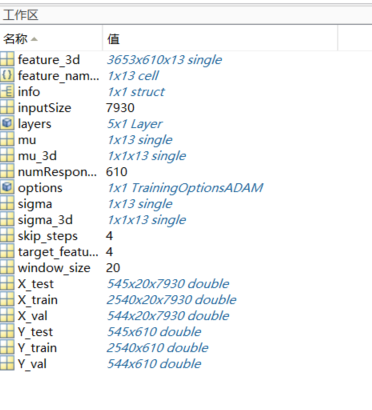
工作区截图:
%%----加载数据,形成特征矩阵,特征举证检查----
%--指定HDF5文件路径
hdf5_file = 'D:\matlab code\soil_data.h5';
% --调用函数构建三维矩阵
[feature_3d, station_ids, time_dates] = hdf5_to_3dmatrix1(hdf5_file);
% --检查结果
% disp('前5个站点ID:');
% disp(station_ids(1:5));
%
% disp('前5个时间点:');
% disp(time_dates(1:5));
%
% disp('三维矩阵维度:');
% disp(size(feature_3d));
% --检查数据维度
% [num_times, num_stations, num_features] = size(feature_3d);
% disp(['数据维度:时间步=', num2str(num_times), ...
% ', 站点数=', num2str(num_stations), ...
% ', 特征数=', num2str(num_features)]);
% --提取-- 时间- 站点- 特征
% test1 = feature_3d(2000:2050, :, 1);
% --查看HDF5文件中的特征名称(无需重新加载数据)
info = h5info('soil_data.h5', '/features');
feature_names = {info.Datasets.Name};
disp('特征顺序:');
disp(feature_names(:)); % 按列显示
%% ----数据归一化----
% --第一步:将三维数据展平为二维矩阵 [时间×站点, 特征]
data = reshape(feature_3d, [], size(feature_3d, 3));
% --第二步:计算每个特征的均值和标准差
mu = mean(data, 1); % 均值, 尺寸: [1, 13]
sigma = std(data, 0, 1); % 标准差, 尺寸: [1, 13]
% --将 mu 和 sigma 转为三维 [1,1,5]
mu_3d = reshape(mu, [1, 1, size(feature_3d, 3)]);
sigma_3d = reshape(sigma, [1, 1, size(feature_3d, 3)]);
% --第三步:归一化(Z-score标准化)
normalized_data = (feature_3d - mu_3d) ./ sigma_3d;
% --归一化检查
denormalized_data = normalized_data .* sigma_3d + mu_3d;
% --反归一化数据与原数据检查
% test1 = feature_3d(2000:2050, :, 4);
% test2 = denormalized_data(2000:2050, :, 4);
% test3 = normalized_data(1:50, :, 4);
%% ----LSTM模型特别适配----
% --生成跳过预测的序列
window_size = 20; % 输入序列长度
skip_steps = 4; % 跳过4步,预测第5天
target_feature = 4; % 预测第4个特征(如温度)
[X, Y] = create_sequences_optimized1(normalized_data, window_size, skip_steps, target_feature);
% 检查尺寸
disp(['X尺寸: ', num2str(size(X))]); % 例如 [76, 20, 50] (100-20-4=76样本)
disp(['Y尺寸: ', num2str(size(Y))]); % 例如 [76, 10] (每个样本预测10个站点的温度)
%% ----内存释放----
clear time_dates station_ids denormalized_data data test1 test2 test3 normalized_data
%% ----训练集、测试集、验证集划分----
% 默认比例划分 (70%/15%/15%)
[X_train, Y_train, X_val, Y_val, X_test, Y_test] = split_sequences(X, Y);
%% ----内存释放----
clear X Y hdf5_file
%% ----lstm网络架构定义----
% 输入参数定义(根据您的数据实际尺寸调整)
inputSize = size(X_train, 3); % = 站点数 × 特征数 (如10站点×5特征=50)
numResponses = size(Y_train, 2); % = 站点数 (如10)
% 网络层定义
layers = [
% 输入层 (必须与X_train的维度匹配)
sequenceInputLayer(inputSize, 'Name', 'input')
% 单LSTM层 (核心时序特征提取)
lstmLayer(128, 'OutputMode', 'last', 'Name', 'lstm1')
% Dropout层 (防止过拟合,比率0.2)
dropoutLayer(0.3, 'Name', 'dropout1')
% 全连接层 (映射到输出维度)
fullyConnectedLayer(numResponses, 'Name', 'fc')
% 回归输出层
regressionLayer('Name', 'output')
];
%% ----训练参数----
options = trainingOptions('adam', ...
'MaxEpochs', 100, ... % 土壤数据建议100-150轮
'MiniBatchSize', 32, ... % 平衡时序连续性与梯度稳定性
'InitialLearnRate', 0.001, ... % Adam标准初始学习率
'GradientThreshold', 1.5, ... % 针对20时间步的LSTM定制
'GradientThresholdMethod', 'global-l2norm',... % 全局梯度裁剪
'Shuffle', 'never', ... % 严格保持土壤温度时序物理性
'ValidationData', {X_val, Y_val}, ...
'ValidationFrequency', ceil(numel(Y_train)/32), ... % 每epoch完整验证一次
'ValidationPatience', 10, ... % 连续10次验证损失未下降则停止
'Plots', 'training-progress', ...
'ExecutionEnvironment', 'auto', ... % 自动选择GPU/CPU
'DispatchInBackground', true); % 后台数据预加载
%% ----模型训练----
[net, trainInfo] = trainNetwork(X_train, Y_train, layers, options);
%% ----模型保存----
save('lstm model.mat', 'net'); % 保存训练好的网络
特征矩阵函数
function [feature_matrix, station_ids, time_dates] = hdf5_to_3dmatrix1(hdf5_filepath)
% 读取HDF5文件并构建三维特征矩阵
% 输入:
% hdf5_filepath - HDF5文件路径
% 输出:
% feature_matrix - 三维特征矩阵(时间×站点×特征)
% station_ids - 站点ID数组
% time_dates - 日期字符串数组
% 1. 读取站点信息
station_ids = h5read(hdf5_filepath, '/stations/id');
num_stations = length(station_ids);
% 2. 读取时间信息
time_dates = h5read(hdf5_filepath, '/time/dates');
num_times = length(time_dates);
% 3. 获取所有特征名称
info = h5info(hdf5_filepath, '/features');
feature_names = {info.Datasets.Name};
num_features = length(feature_names);
% 4. 预分配三维矩阵 (时间×站点×特征)
feature_matrix = zeros(num_times, num_stations, num_features, 'single');
% 5. 逐个特征读取并填充矩阵
for feat_idx = 1:num_features
feat_name = feature_names{feat_idx};
feat_path = ['/features/' feat_name];
% 读取特征数据 (假设数据是站点×时间的二维矩阵)
feat_data = h5read(hdf5_filepath, feat_path);
% 转置数据使其变为时间×站点
feat_data = feat_data';
% 将特征数据放入三维矩阵
feature_matrix(:, :, feat_idx) = feat_data;
end
% 6. 转换站点ID为字符串数组(如果原始数据不是)
if isnumeric(station_ids)
station_ids = string(num2str(station_ids'));
else
station_ids = string(station_ids);
end
% 7. 转换日期为字符串数组(如果原始数据不是)
if isnumeric(time_dates)
time_dates = string(num2str(time_dates'));
else
time_dates = string(time_dates);
end
disp(['成功构建三维特征矩阵,维度为: ' num2str(size(feature_matrix))]);
disp(['包含 ' num2str(num_features) ' 个特征: ' strjoin(feature_names, ', ')]);
end
lstm样本函数
%% --LSTM模型特别适配函数
function [X, Y] = create_sequences_optimized(data, window_size, skip_steps, target_feature)
[T, S, F] = size(data);
num_samples = T - window_size - skip_steps;
% 预分配内存 - 注意这里的第三维应该是S*F
X = zeros(num_samples, window_size, S * F);
Y = zeros(num_samples, S);
for i = 1:num_samples
% 获取窗口数据并保持站点×特征的结构
window_data = data(i:i+window_size-1, :, :);
% 重塑为[window_size, S*F]的形状
X(i, :, :) = reshape(window_data, window_size, S*F);
% 目标值
Y(i, :) = data(i+window_size+skip_steps, :, target_feature);
end
end
划分训练集、测试集的函数。
%% ----训练集、测试集、验证集划分函数----
function [X_train, Y_train, X_val, Y_val, X_test, Y_test] = split_sequences(X, Y, ratios)
% 严格按时间顺序划分数据集(保持double精度)
% 输入:
% X: 输入样本 [num_samples, window_size, num_features]
% Y: 输出标签 [num_samples, num_stations]
% ratios: 结构体包含Train/Val/Test比例(默认0.7/0.15/0.15)
% 输出:
% 划分后的训练集、验证集、测试集
% 参数检查(包含所有比例字段)
arguments
X double
Y double
ratios.Train (1,1) double {mustBePositive, mustBeLessThan(ratios.Train,1)} = 0.7
ratios.Val (1,1) double {mustBePositive, mustBeLessThan(ratios.Val,1)} = 0.15
ratios.Test (1,1) double {mustBePositive, mustBeLessThan(ratios.Test,1)} = 0.15
end
% 验证比例总和为1(含Test字段)
assert(abs(ratios.Train + ratios.Val + ratios.Test - 1) < 1e-6, ...
'比例总和必须为1 (当前总和=%.2f)', ratios.Train + ratios.Val + ratios.Test);
% 验证输入一致性
assert(size(X,1) == size(Y,1), 'X和Y的样本数不一致!');
% 计算划分点
num_samples = size(X,1);
train_end = floor(ratios.Train * num_samples);
val_end = train_end + floor(ratios.Val * num_samples);
% 核心划分(保持double精度)
X_train = X(1:train_end, :, :);
Y_train = Y(1:train_end, :);
X_val = X(train_end+1:val_end, :, :);
Y_val = Y(train_end+1:val_end, :);
X_test = X(val_end+1:end, :, :);
Y_test = Y(val_end+1:end, :);
% 边界安全检查
assert(val_end < num_samples, '验证集索引越界');
assert(size(X_train,1) + size(X_val,1) + size(X_test,1) == num_samples, ...
'样本总数不匹配');
% 打印划分结果
disp('==== 数据集划分完成 ====');
disp(['训练集: ', num2str(size(X_train,1)), '样本 (', num2str(ratios.Train*100), '%)']);
disp(['验证集: ', num2str(size(X_val,1)), '样本 (', num2str(ratios.Val*100), '%)']);
disp(['测试集: ', num2str(size(X_test,1)), '样本 (', num2str(ratios.Test*100), '%)']);
end
训练集X_train为三维矩阵(样本数×时间步数×特征),其第三维的应该与lstm输入层对应,我认为我已经完全对应。但还是报错







