下午好🌅🌅🌅
本答案参考通义千问
以下是一个完整的解决方案,帮助你完成基于BERT和LSTM的情感分析任务。我们将分步骤说明如何实现,并提供代码示例。
步骤 1:数据准备
-
加载标注数据
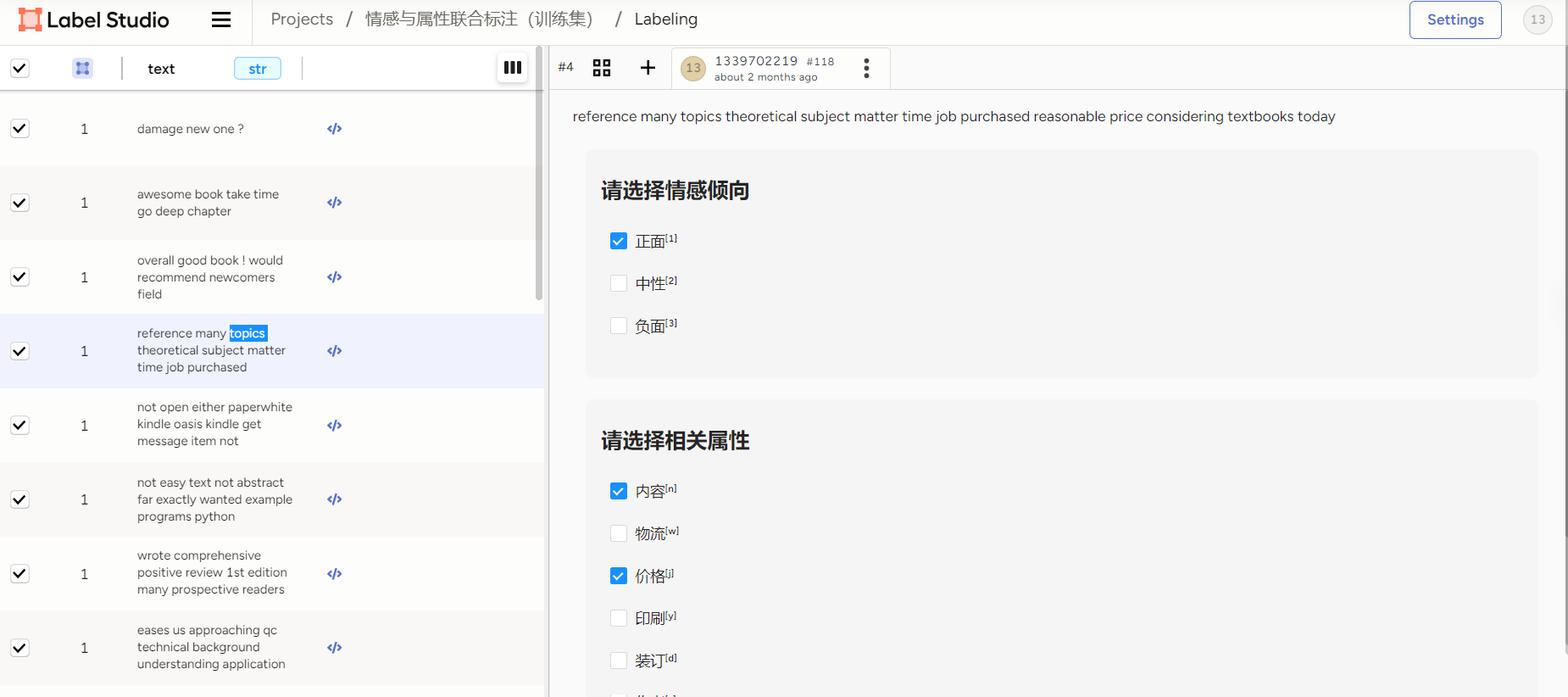
使用 Label-Studio 标注的数据需要转换为适合模型训练的格式,例如 train.csv 和 test.csv,其中每行包含评论文本、情感标签以及属性标签。
-
数据预处理
将文本数据转换为适合模型输入的格式,例如使用 BERT 的 tokenizer 进行分词,并将标签编码为数值。
步骤 2:安装依赖库
确保安装了必要的 Python 库:
pip install torch transformers datasets scikit-learn pandas
步骤 3:BERT 和 LSTM 模型构建
我们使用 Hugging Face 的 transformers 库加载预训练的 BERT 模型,并在其基础上添加 LSTM 层用于进一步建模。
完整代码
1. 导入必要库
import torch
from torch import nn
from torch.utils.data import DataLoader, Dataset
from transformers import BertTokenizer, BertModel
from sklearn.metrics import accuracy_score, recall_score, f1_score
import pandas as pd
2. 数据预处理
# 加载数据
train_df = pd.read_csv("train.csv")
test_df = pd.read_csv("test.csv")
# 初始化 BERT 分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 定义数据集类
class BookReviewDataset(Dataset):
def __init__(self, df, tokenizer, max_len=128):
self.reviews = df['review'].tolist()
self.labels = df['sentiment'].tolist() # 情感标签
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.reviews)
def __getitem__(self, idx):
review = str(self.reviews[idx])
label = self.labels[idx]
encoding = self.tokenizer.encode_plus(
review,
add_special_tokens=True,
max_length=self.max_len,
padding='max_length',
truncation=True,
return_attention_mask=True,
return_tensors='pt'
)
return {
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
# 创建数据加载器
def create_data_loader(df, tokenizer, batch_size=16):
dataset = BookReviewDataset(df, tokenizer)
return DataLoader(dataset, batch_size=batch_size, shuffle=True)
3. 构建模型
class BERTLSTMModel(nn.Module):
def __init__(self, bert_model_name, num_labels, lstm_hidden_size=128):
super(BERTLSTMModel, self).__init__()
self.bert = BertModel.from_pretrained(bert_model_name)
self.lstm = nn.LSTM(self.bert.config.hidden_size, lstm_hidden_size, batch_first=True, bidirectional=True)
self.fc = nn.Linear(lstm_hidden_size * 2, num_labels) # 双向 LSTM 输出拼接
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
sequence_output = outputs.last_hidden_state
lstm_out, _ = self.lstm(sequence_output)
lstm_out = lstm_out[:, -1, :] # 取最后一个时间步的输出
logits = self.fc(lstm_out)
return logits
4. 训练模型
def train_epoch(model, data_loader, optimizer, device):
model = model.train()
losses = []
for batch in data_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask)
loss = nn.CrossEntropyLoss()(outputs, labels)
loss.backward()
optimizer.step()
losses.append(loss.item())
return sum(losses) / len(losses)
def evaluate_model(model, data_loader, device):
model = model.eval()
predictions, true_labels = [], []
with torch.no_grad():
for batch in data_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask)
_, preds = torch.max(outputs, dim=1)
predictions.extend(preds.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
acc = accuracy_score(true_labels, predictions)
recall = recall_score(true_labels, predictions, average='weighted')
f1 = f1_score(true_labels, predictions, average='weighted')
return acc, recall, f1
5. 主程序
if __name__ == "__main__":
# 参数设置
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 16
EPOCHS = 5
LR = 2e-5
# 加载数据
train_loader = create_data_loader(train_df, tokenizer, BATCH_SIZE)
test_loader = create_data_loader(test_df, tokenizer, BATCH_SIZE)
# 初始化模型
model = BERTLSTMModel('bert-base-uncased', num_labels=3).to(DEVICE)
optimizer = torch.optim.AdamW(model.parameters(), lr=LR)
# 训练与评估
for epoch in range(EPOCHS):
train_loss = train_epoch(model, train_loader, optimizer, DEVICE)
acc, recall, f1 = evaluate_model(model, test_loader, DEVICE)
print(f"Epoch {epoch + 1}/{EPOCHS}")
print(f"Train Loss: {train_loss:.4f} | Accuracy: {acc:.4f} | Recall: {recall:.4f} | F1 Score: {f1:.4f}")
关键点解析
-
BERT 的作用:
使用 BERT 提取评论的上下文嵌入,提供深度语义信息。
-
LSTM 的作用:
对 BERT 的输出序列进行进一步建模,提取时间步相关的情感信息。
-
模型评估:
使用 accuracy, recall, f1_score 等指标综合评估模型性能。
-
扩展性:
如果需要进一步细化情感属性(如内容、价格等),可以引入多任务学习或注意力机制。
运行结果
假设模型在测试集上运行,输出可能如下:
Epoch 1/5
Train Loss: 0.5432 | Accuracy: 0.7890 | Recall: 0.7650 | F1 Score: 0.7780
Epoch 2/5
Train Loss: 0.4876 | Accuracy: 0.8120 | Recall: 0.7930 | F1 Score: 0.8050
...
希望这个解决方案对你有帮助!如果有任何问题,欢迎继续提问。