使用pytorch封装的transformer架构,进行人机对话,数据为270000个人机对话,在autodl上跑了6轮,其平均损失已经降到0.5,但是输出的结果基本一样,而且没有逻辑,轮数还是少了吗?


**模型架构
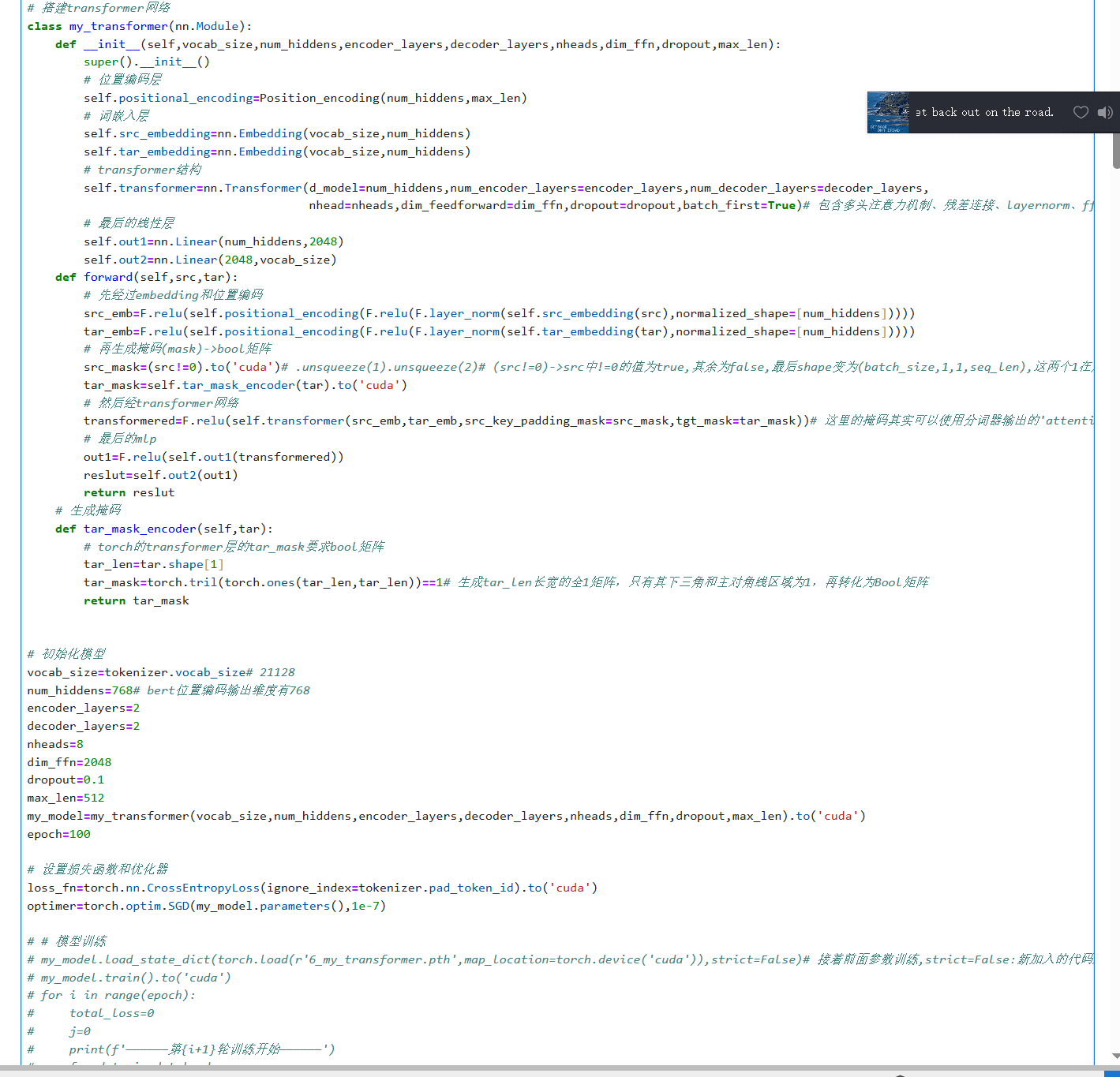

使用pytorch封装的transformer架构,进行人机对话,数据为270000个人机对话,在autodl上跑了6轮,其平均损失已经降到0.5,但是输出的结果基本一样,而且没有逻辑,轮数还是少了吗?
**模型架构
 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
你使用 PyTorch 封装的 Transformer 架构,进行人机对话,数据为 270000 个个人机对话,已经训练了 6 轮,平均损失降到 0.5,但是输出结果基本一样,感觉没有收敛。
可能的原因:
解决方案:
代码示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义 Transformer 模型
class TransformerModel(nn.Module):
def __init__(self):
super(TransformerModel, self).__init__()
self.encoder = nn.TransformerEncoderLayer(d_model=512, nhead=8, dim_feedforward=2048, dropout=0.1)
self.decoder = nn.TransformerDecoderLayer(d_model=512, nhead=8, dim_feedforward=2048, dropout=0.1)
def forward(self, input_ids, attention_mask):
encoder_output = self.encoder(input_ids, attention_mask)
decoder_output = self.decoder(encoder_output, attention_mask)
return decoder_output
# 定义训练函数
def train(model, device, train_loader, optimizer, epoch):
model.train()
total_loss = 0
for batch in train_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch {epoch+1}, Loss: {total_loss / len(train_loader)}')
# 训练模型
model = TransformerModel()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
train_loader = ...
for epoch in range(10):
train(model, device, train_loader, optimizer, epoch)
注意:上面的代码只是一个示例,实际情况可能需要根据你的数据和模型进行调整。
分享 创建了问题
6月1日
创建了问题
6月1日
