
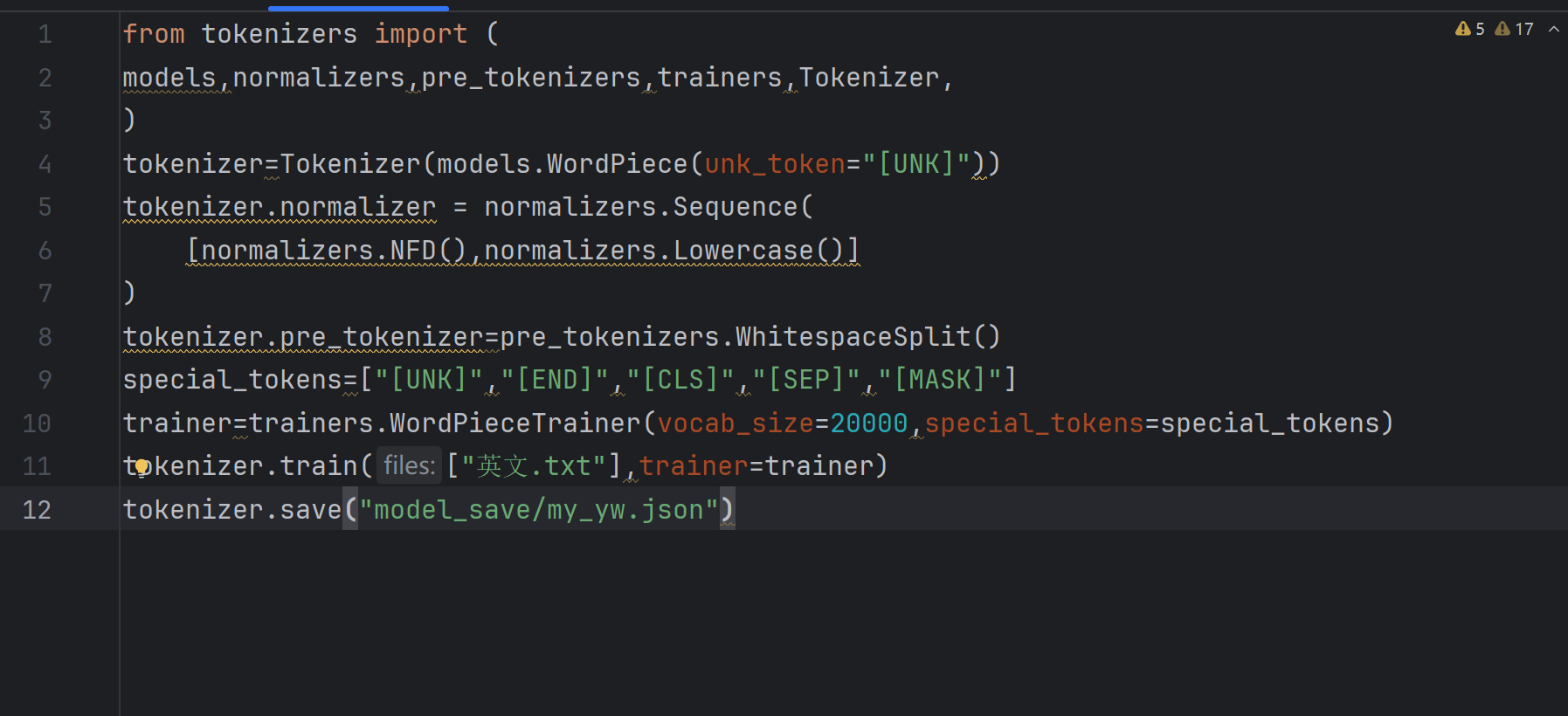
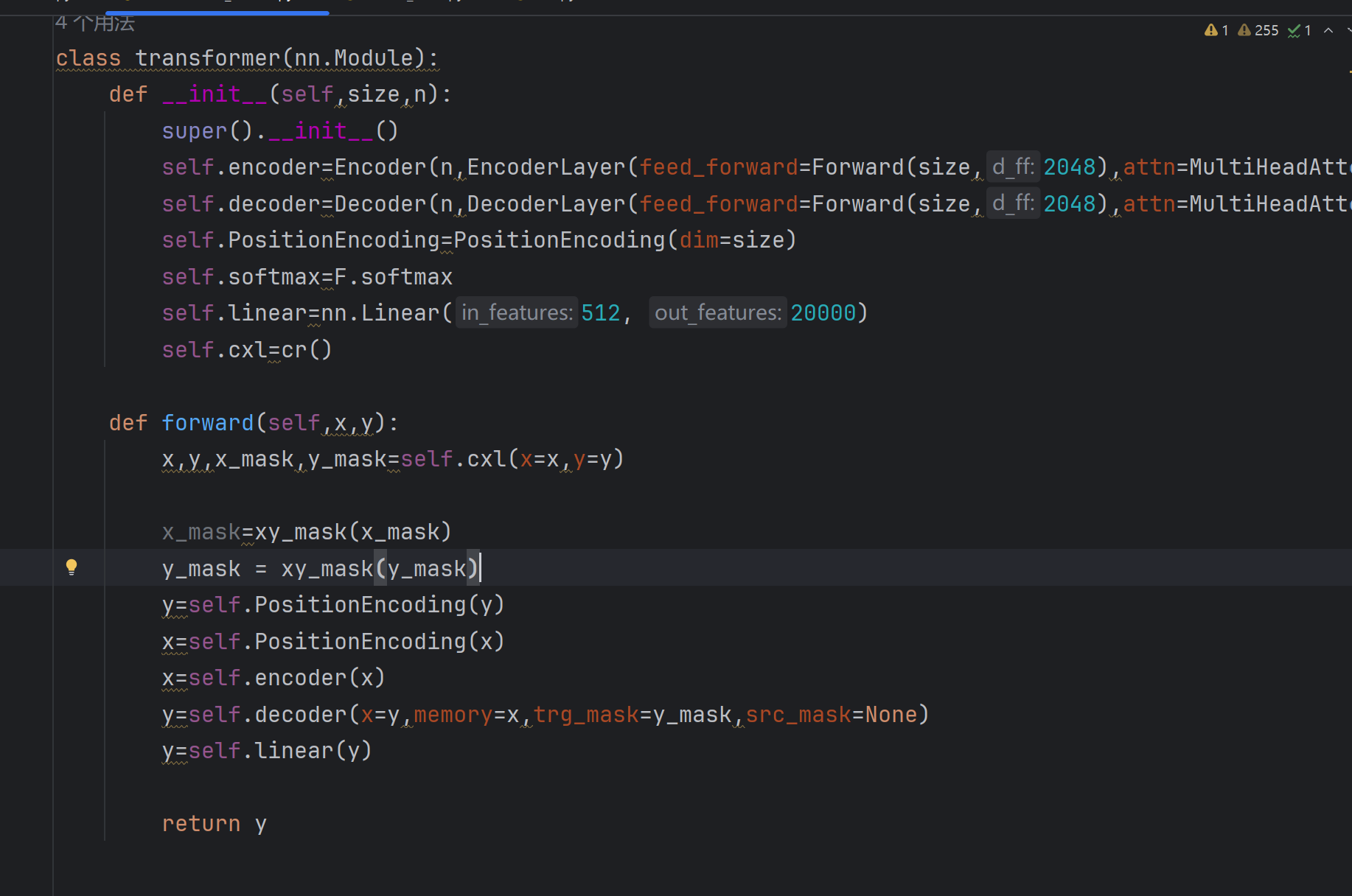
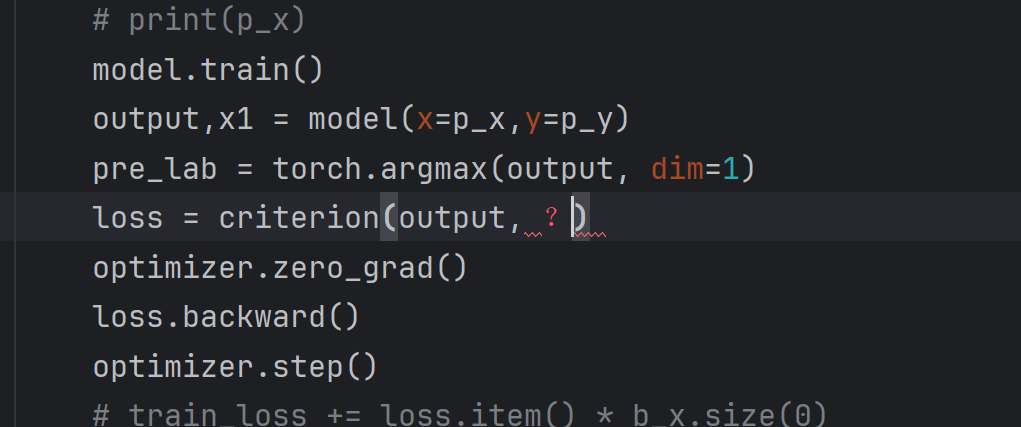
本人是刚接触深度学习不久,想做一个翻译程序,模型搭好了,词表也做好了,但是这个训练时y的真实值,该怎么转换输入?有人能指点我一下吗😭

本人是刚接触深度学习不久,想做一个翻译程序,模型搭好了,词表也做好了,但是这个训练时y的真实值,该怎么转换输入?有人能指点我一下吗😭
 分享
分享
我曾经遇到过类似的问题,当时也是在使用Transformer模型进行翻译任务时,对训练时目标真实值(y)的输入转换方式感到困惑。结合你提供的代码和问题描述,下面为你分析并给出解决方案。
你的目标是构建一个翻译程序,目前已搭建好Transformer模型并完成词表构建,但不清楚训练时如何将目标语言真实值(y)转换为模型可接收的输入。核心问题在于目标序列的预处理流程(如分词、编码、对齐)以及模型训练时标签的设置方式。
思路:
将目标语言句子通过词表分词为token序列,再转换为模型所需的整数编码,并在训练时作为labels传入模型。需注意目标序列需进行左移处理(即解码器输入为[SOS]+目标序列[:-1],标签为目标序列[1:]+[EOS]),以避免自回归模型提前看到完整标签。
关键步骤:
[END])。 [CLS],并截断到最大长度。 [END],并与解码器输入对齐(长度一致)。 labels参数传入模型的前向传播函数。代码片段:
# 假设已有分词器 tokenizer 和目标句子列表 tgt_sentences
# 1. 对目标句子进行编码(含结束符)
tgt_tokenized = [tokenizer.encode(sent, add_special_tokens=False) for sent in tgt_sentences] # 不添加默认特殊 token
tgt_labels = []
decoder_inputs = []
for tokens in tgt_tokenized:
# 标签:末尾添加 [END]
label = tokens + [tokenizer.token_to_id("[END]")]
# 解码器输入:开头添加 [CLS],并左移一位(标签是解码器输入的下一个 token)
decoder_input = [tokenizer.token_to_id("[CLS]")] + tokens
tgt_labels.append(label)
decoder_inputs.append(decoder_input)
# 2. 转换为张量并填充到固定长度
max_len = max(len(seq) for seq in tgt_labels)
tgt_labels = [seq + [tokenizer.pad_token_id]*(max_len - len(seq)) for seq in tgt_labels]
decoder_inputs = [seq + [tokenizer.pad_token_id]*(max_len - len(seq)) for seq in decoder_inputs]
tgt_labels = torch.tensor(tgt_labels)
decoder_inputs = torch.tensor(decoder_inputs)
# 3. 训练时传入模型(假设模型输入为 src_ids, decoder_inputs, labels=tgt_labels)
outputs = model(src_ids, decoder_input_ids=decoder_inputs, labels=tgt_labels)
loss = outputs.loss
思路:
直接将目标序列的完整token编码作为标签,利用Teacher Forcing机制在训练时将目标序列前一时刻的输出作为下一时刻的输入。此方案无需手动处理解码器输入,模型会自动处理对齐。
关键步骤:
labels,同时将其作为解码器输入(需注意移除最后一个 token,避免标签泄露)。 代码片段:
# 假设 tgt_sentences 为目标句子列表
tgt_encoded = tokenizer(tgt_sentences, padding=True, truncation=True, return_tensors="pt")
# 解码器输入:目标序列(不含最后一个 token)
decoder_input_ids = tgt_encoded.input_ids[:, :-1]
# 标签:目标序列(不含第一个 token,且填充值需设为 -100 以忽略损失计算)
labels = tgt_encoded.input_ids[:, 1:].masked_fill(tgt_encoded.input_ids[:, 1:] == tokenizer.pad_token_id, -100)
# 训练时传入模型
outputs = model(src_input_ids, decoder_input_ids=decoder_input_ids, labels=labels)
loss = outputs.loss
优势:
核心逻辑:
通过显式构建解码器输入和标签的左移关系,确保模型在训练时不会提前接触到目标序列的未来信息。例如,目标序列为[A, B, C, END],则解码器输入为[CLS, A, B, C],标签为[A, B, C, END],模型通过预测每个位置的下一个 token 进行学习。
希望以上方案能帮你解决问题!如果对代码实现或原理有疑问,可以继续留言。请楼主采纳~
分享 系统已结题
6月17日
系统已结题
6月17日 已采纳回答
6月9日
修改了问题
6月8日
创建了问题
6月8日
已采纳回答
6月9日
修改了问题
6月8日
创建了问题
6月8日

