我利用keras的神经网络训练一个模型,被训练的数据是一个很大的二维数组,每一行是一个类别,总共有3种类别。被训练出的模型中包括3种类别(暂且称为A,B,C)。现在B类的预测准确率太高了,而A和C类的预测准确率较低,我想在把B类准确率适当减低的情况下来提高A和C类的预测准确率。请问该怎么操作?
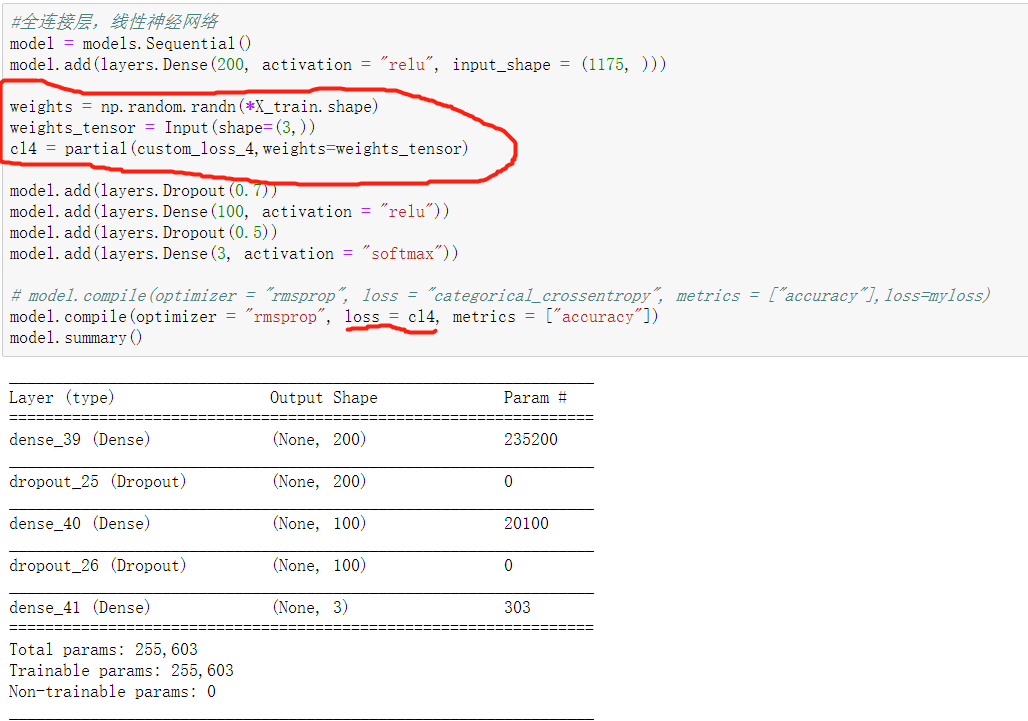
代码如下,我从网上查了一些代码,自己不是特别明白,尝试后,出现了错误。请问该如何修改?下面添加的图片中被划红线圈住的代码是添加上去的,最终运行出错了,请问怎么修改,或者重新帮我写一个权重损失代码代码,跪谢
def custom_loss_4(y_true, y_pred, weights):
return K.mean(K.abs(y_true - y_pred) * weights)
model = models.Sequential()
model.add(layers.Dense(200, activation = "relu", input_shape = (1175, )))
weights = np.random.randn(*X_train.shape)
weights_tensor = Input(shape=(3,))
cl4 = partial(custom_loss_4,weights=weights_tensor)
model.add(layers.Dropout(0.7))
model.add(layers.Dense(100, activation = "relu"))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(3, activation = "softmax"))
model.compile(optimizer = "rmsprop", loss = cl4, metrics = ["accuracy"])
model.summary()
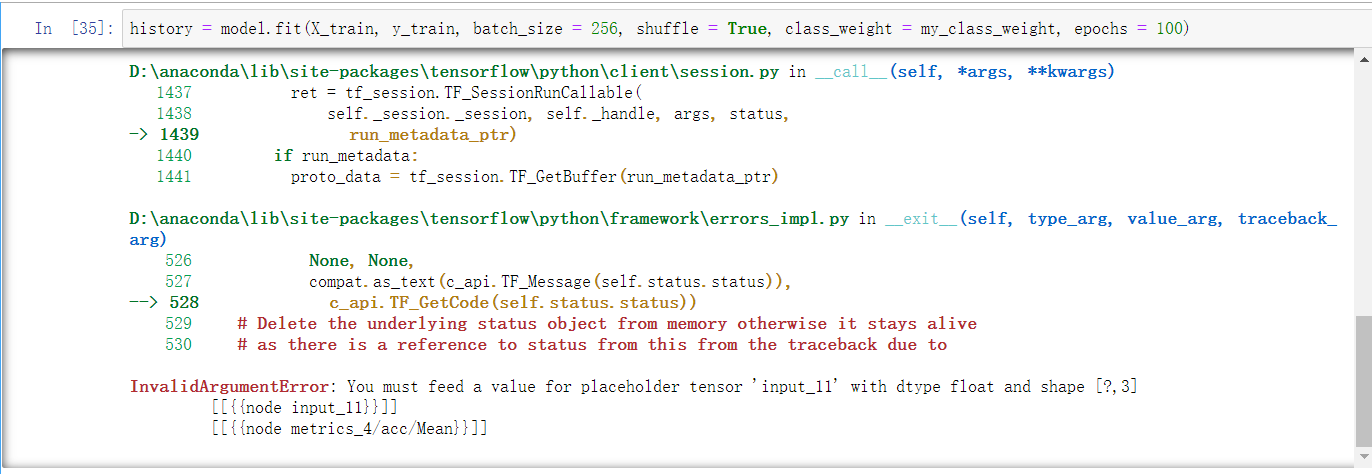
补充一下:我在前面对数据做过了不平衡调整,定义的函数如下:
def calc_class_weight(total_y):
my_class_weight = class_weight.compute_class_weight("balanced", np.unique(total_y), total_y)
return my_class_weight

python如何自定义权重损失函数?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 蔡能教授,网站特聘专家 2019-10-13 16:19关注
蔡能教授,网站特聘专家 2019-10-13 16:19关注from keras.layers import Input,Embedding,LSTM,Dense,Lambda
from keras.layers.merge import dot
from keras.models import Model
from keras import backend as Kword_size = 128
nb_features = 10000
nb_classes = 10
encode_size = 64
margin = 0.1embedding = Embedding(nb_features,word_size)
lstm_encoder = LSTM(encode_size)def encode(input):
return lstm_encoder(embedding(input))q_input = Input(shape=(None,))
a_right = Input(shape=(None,))
a_wrong = Input(shape=(None,))
q_encoded = encode(q_input)
a_right_encoded = encode(a_right)
a_wrong_encoded = encode(a_wrong)q_encoded = Dense(encode_size)(q_encoded) #一般的做法是,直接讲问题和答案用同样的方法encode成向量后直接匹配,但我认为这是不合理的,我认为至少经过某个变换。
right_cos = dot([q_encoded,a_right_encoded], -1, normalize=True)
wrong_cos = dot([q_encoded,a_wrong_encoded], -1, normalize=True)loss = Lambda(lambda x: K.relu(margin+x[0]-x[1]))([wrong_cos,right_cos])
model_train = Model(inputs=[q_input,a_right,a_wrong], outputs=loss)
model_q_encoder = Model(inputs=q_input, outputs=q_encoded)
model_a_encoder = Model(inputs=a_right, outputs=a_right_encoded)model_train.compile(optimizer='adam', loss=lambda y_true,y_pred: y_pred)
model_q_encoder.compile(optimizer='adam', loss='mse')
model_a_encoder.compile(optimizer='adam', loss='mse')model_train.fit([q,a1,a2], y, epochs=10)
#其中q,a1,a2分别是问题、正确答案、错误答案的batch,y是任意形状为(len(q),1)的矩阵解决 无用评论 打赏举报 分享
- 2025-12-27 11:53来朝三博士的博客 通过TensorFlow,我们可以灵活设计自定义损失函数,将业务代价直接编码进模型优化过程。无论是简单的加权调整,还是实现Focal Loss、Soft Dice等复杂可微形式,只需确保使用可导的TensorFlow操作,即可无缝集成到...
- 2025-12-12 09:41年近半百的博客 本文介绍如何在LLama-Factory中自定义损失函数,提升模型训练的精细化控制能力。通过注册机制和配置化管理,用户可灵活替换或组合损失函数,适用于样本不均衡、多任务学习等复杂场景,结合LoRA实现高效微调。
- 2025-12-27 06:59念区的博客 通过TensorFlow的自定义损失机制,可将领域知识融入模型训练,如处理样本不均衡、边界敏感分割或金融反欺诈中的非对称代价。支持函数式、类式及闭包实现,兼顾灵活性与工程稳定性,是提升模型实用性的关键技能。
- 2025-01-01 05:00道友老李的博客 在 TensorFlow 中,自定义损失函数和层(Layer)是扩展框架功能、实现特定需求或优化模型性能的重要手段。下面我将详细介绍如何在 TensorFlow 中创建自定义损失函数和自定义层。
- 2025-09-13 13:45galaxy‘的博客 本文介绍了在LightGBM、XGBoost和CatBoost中实现自定义缩放误差损失函数和评估指标的方法。传统的MSE和MAE对预测值赋予相同权重,而缩放误差通过除以真实值来更关注相对误差,适用于数值范围变化大的场景。文章详细...
- 2023-10-10 10:57无水先生的博客 TensorFlow 2发布已经接近5年时间,不仅继承了Keras快速上手和易于使用的特性,同时还扩展了原有Keras所不支持的分布式训练的特性。...这是本系列的第三部分,我们将创建代价函数并在 TensorFlow 2 中使用它们。
- 2025-10-19 21:37轻筠的博客 本文介绍了在PyTorch中实现自定义损失函数的方法。主要内容包括:为什么要自定义损失函数(处理特殊数据、加入领域知识等),如何准备数据并构建简单的神经网络模型,以及实现自定义均方误差损失函数的详细步骤。...
- 2025-03-15 17:34WHCIS的博客 'swish': Swish() # 使用自定义激活。
- 2025-12-31 08:09Xi Zi的博客 深入探讨如何在PyTorch中实现Focal Loss等自定义损失函数,解决类别不平衡问题,同时利用Miniconda搭建可复现的Python 3.11深度学习环境,有效应对依赖冲突与版本漂移,提升团队协作效率与实验稳定性。
- 2025-02-15 16:16AI Agent首席体验官的博客 假设我们有一个Series,希望通过apply()# 创建一个Series# 自定义函数# 使用apply应用自定义函数0 11 42 93 16假设我们有一个DataFrame# 创建一个DataFrame})# 自定义函数# 使用apply在每一列上应用自定义函数A 2B 2...
- 没有解决我的问题, 去提问
