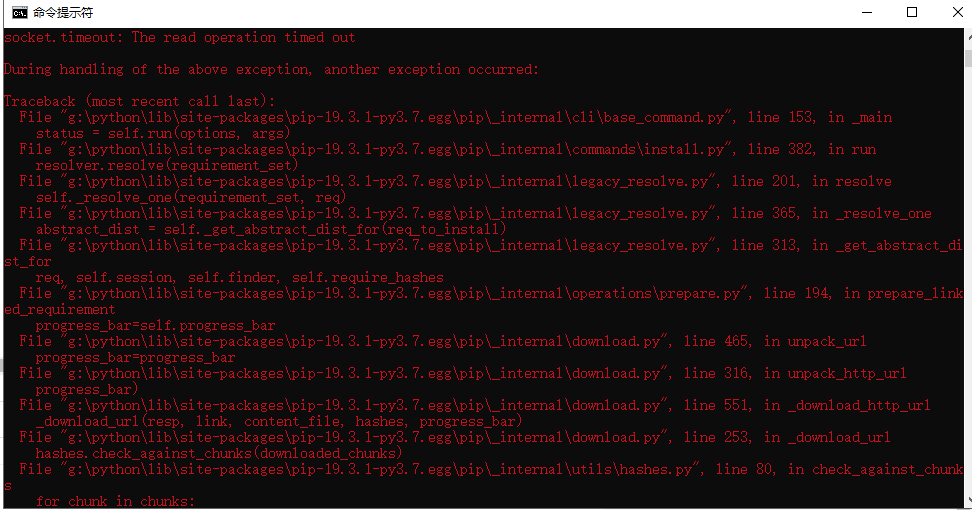
请问我安装pandas时总是安装不了,在官网上下载了pandas pip 那个文件以后能安装,但是后面还会再有一个安装。就卡在第二个安装上,而且,直接pip install pandas也会出现同样问题。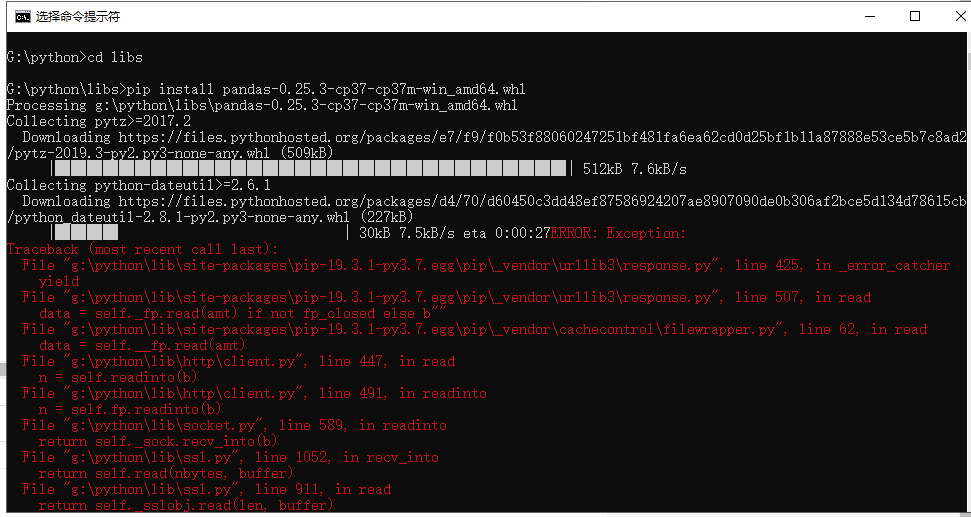

python pandas安装遇到问题怎么办?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


3条回答 默认 最新
- 2020-03-24 15:02回答 1 已采纳 按这个形式写, 应该能达到你的要求 ``` check_flag = 'A' for i in range(数据总量) if check_flag == 'A': if
- 2021-06-23 00:15回答 1 已采纳 windows的话命令行输入pip install pandas,前提是把python目录添加到环境变量,安装python的时候有选项可以勾选。linux应该直接pip就可以。
- 2021-12-10 15:57回答 2 已采纳 代码: #!/bin/env python import pandas as pd from pandas.core.frame import DataFrame def getValue(raw
- 2022-08-17 23:09红乘以白的博客 Python安装Pandas库的三种方法
- 2022-07-26 09:06回答 2 已采纳 groupby可以尝试下
- 2022-03-30 21:43回答 3 已采纳 试试这个 births[births['gender']=='M'].groupby('year').count()
- 2021-08-13 18:07回答 3 已采纳 图中所示不是错误,是没有设置显示中文。可尝试用在matplotlib中设置中文显示方法,在开头导入import matplotlib.pyplot as plt 用两行代码:plt.rcParams[
- 2017-11-10 15:44python安装pandas python安装pandas python安装pandas python安装pandas
- 2021-08-04 21:58回答 1 已采纳 你这个pandas版本要求的太低了,实在不行,你再下一个低版本的python试试,看看能不能管用,要么你就下高版本的pandas如果有用,希望采纳~
- 2020-04-14 13:18回答 1 已采纳 这样不行吗? ``` data = pd.read_csv('./moviecsv.csv', sep=',' ,encoding='gbk') ```
- 2022-02-12 15:47回答 4 已采纳 转换后的data前面的1,2,3事行号吗? outdata="" for i in list(data): # 转换为字符串 outdata+=",".join([str(s) for
- 2021-01-14 06:58weixin_39593340的博客 如何优雅的安装Python的pandas1、可以使用pip install pandas安装2、可以安装anaconda,它里面已经集成了pandas/matplotlib/numpy等包Pandas模块用于做什么?Pandas是python最常用的库之一。主要用于数据分析和处理...
- 2021-11-04 09:23回答 1 已采纳 在函数random_choice中不用列表添加,直接返回符合条件的值即可,或者用 res[0]取出列表元素,在数据框中列数据中就就会去掉[]了。
- 2020-12-11 09:42薛易清的博客 I wrote some code to build my own EMA/MACD, but have decided to give Pandas a try instead.I am using this website below as a basic understanding of EMA and trying to get pandas to give me the same ans...
- 2019-10-11 10:30明的大世界的博客 python安装pandas包过程中遇到的问题总结 安装pandas包时,在网上看的教程有手动安装和自动安装两个方法:手动安装是手动安装pandas包,在安装pandas第三方模块时,需要依赖好多环境配置,为了省去这些配置,可以...
- 没有解决我的问题, 去提问



悬赏问题
- ¥50 comfyui下连接animatediff节点生成视频质量非常差的原因
- ¥20 有关区间dp的问题求解
- ¥15 多电路系统共用电源的串扰问题
- ¥15 slam rangenet++配置
- ¥15 有没有研究水声通信方面的帮我改俩matlab代码
- ¥15 对于相关问题的求解与代码
- ¥15 ubuntu子系统密码忘记
- ¥15 信号傅里叶变换在matlab上遇到的小问题请求帮助
- ¥15 保护模式-系统加载-段寄存器
- ¥15 电脑桌面设定一个区域禁止鼠标操作