代码最后加了
if __name__ == '__main__':
tf.app.run()
显示错误
AttributeError: module 'tensorflow' has no attribute 'app'
一直没找到怎么回事,也在cmd里试了pip install app,也不行。想请问下这是什么问题导致的。
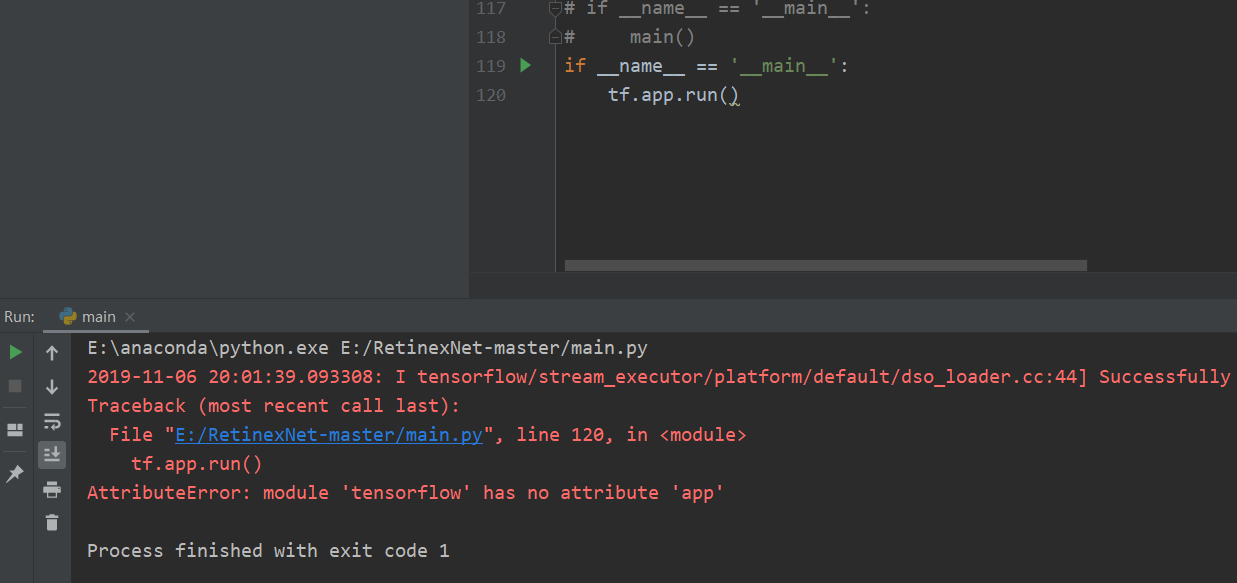
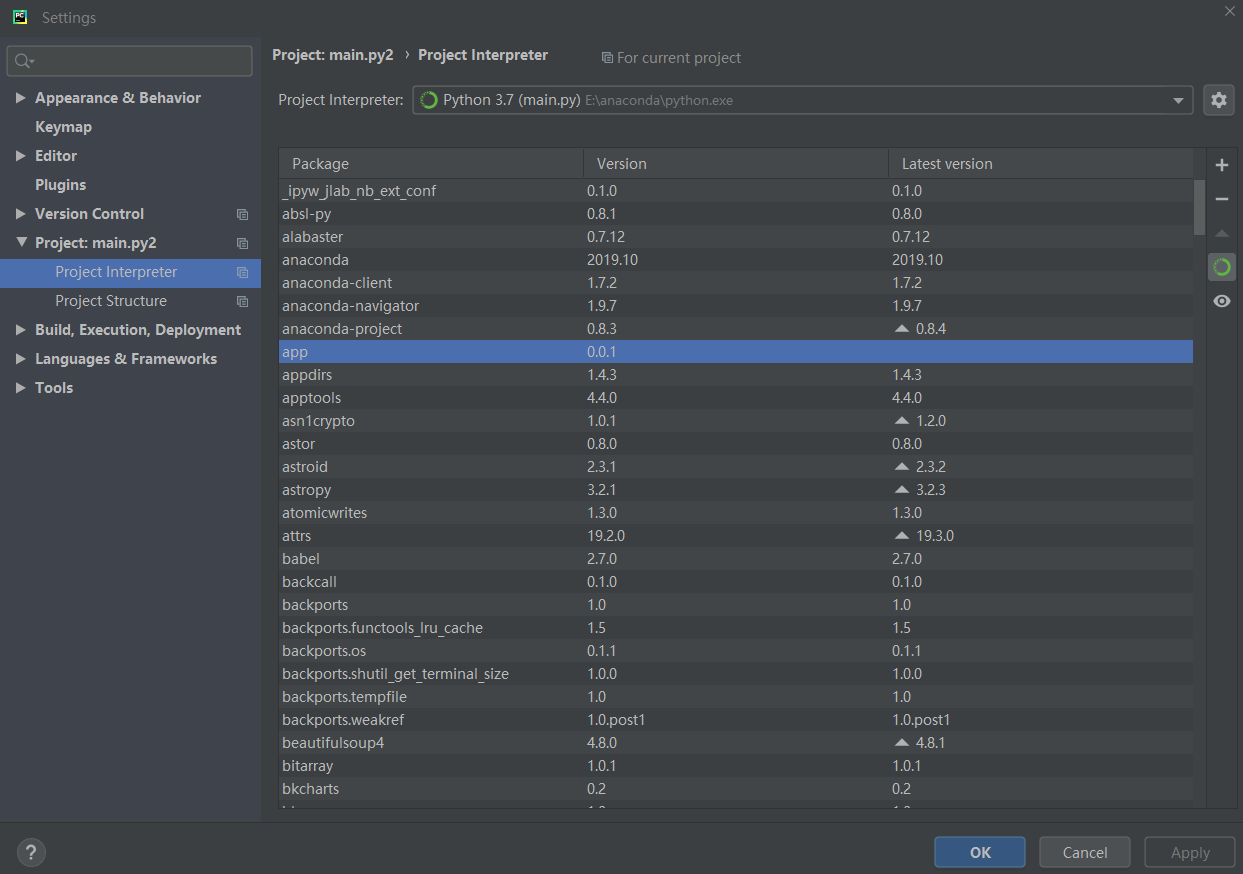

代码最后加了
if __name__ == '__main__':
tf.app.run()
显示错误
AttributeError: module 'tensorflow' has no attribute 'app'
一直没找到怎么回事,也在cmd里试了pip install app,也不行。想请问下这是什么问题导致的。
 分享
分享

